
Amber Group:全方位解读零知识证明



1. 引言
零知识证明允许一方在不需要透露任何额外信息的前提下,向另一方进行真实性证明。因此可以用来保护隐私,在隐藏所有细节的情况下证实交易的有效性。某些特定零知识协议在验证零知识证明上具有便利性,这很重要,例如STARK和SNARK。这些协议生成的证明较小,验证此类证明也会快很多。这很适合资源有限的区块链,并且在解决加密行业的可扩展性问题上尤为重要。除此之外,零知识技术的其他用例还包括:
-
跨链桥——使用零知识证明(ZKP)进行状态转换或验证交易,例如Alogrand ASP,Mystiko
-
DID(去中心化 ID)——在避免泄露详细信息的前提下,证明某个账号或实体具有某些"特征",例如 Sismo,First Batch
-
社区治理——用于匿名投票,并且在经过实践考验和广泛采用后,该用例可以延展至现实社会的治理中
-
财务报表——实体可以在避免透露确切财务数据的前提下,证明其符合某些特定标准
-
云服务的完整性——帮助云服务供应商更好地执行任务
……
一个典型的零知识系统工作原理如下:工程师首先用领域特定语言(DSL)编写要验证的陈述,然后将其编译成适合零知识的格式,比如算数环路。使用该格式生成参数后,证明系统会将这些参数与其见证的保密信息一起作为输入值来运行证明计算。通过相对简单的计算,验证者可以凭参数和证明来决定是否通过验证。使用零知识汇总的情况下,程序或合约本身部署在layer2上,而编译过程、参数和证明的生成将由部分layer2节点在链下执行,之后在 以太坊 主网上发布和完成验证。
一个典型的零知识系统
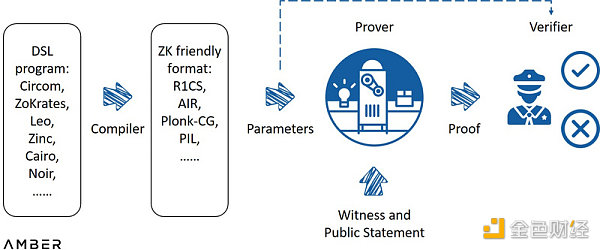
来源:ZK Whiteboard Sessions - Module One,由 Dan Boneh教授撰写
已有多个优秀的证明系统面世,例如Marlin、Plonky2、Halo2等。不同的证明系统在生成证明的大小、验证所需时间和是否需要可信设置等特性之间有不同的侧重。经过这几年的探索,无论陈述多么复杂,都有可能实现恒定的证明大小(几百字节)和较短的验证时间(几毫秒)。
然而,证明生成的复杂性与算术环路大小几乎成线性关系,所以难度甚至可能达到原始任务的数百倍。因为证明者至少需要阅读和评估环路,这就可能需要几秒钟到几分钟,甚至几小时。算力成本高和证明时间长一直是零知识技术进步和大规模应用的主要障碍。
硬件加速可以帮助打破瓶颈。借助算法或软件优化将多个任务分配给最适合的硬件,这将实现相辅相成。
本报告旨在帮助读者了解市场格局、零知识技术对挖矿市场产生的影响、以及潜在机会。报告由三部分组成:
-
不同项目的实际用例和最新趋势。
-
基于GPU、FPGA、ASIC的加速解决方案。
-
结语
2. 用例
列举零知识用例将有助于说明市场是如何演变的。因为不同类别有不同需求,所以硬件供给也牵连其中。在本节的最后,我们还将简要比较ZKP和PoW(尤其是对于 比特币 )。
2.1 新兴的区块链及其差异化需求
当前使用零知识技术的新兴区块链是硬件加速的主要需求方,大致分为扩展解决方案和保护隐私的区块链。零知识的Rollup或Volition在链下执行交易,并通过“数据调用”功能提交简洁的验证证明。保护隐私的区块链使用ZKP让用户在避免披露交易细节的前提下,确保发起交易的有效性。
这些区块链通过使用不同的证明系统来权衡证明大小、验证时间、可信设置等特性。例如,Plonk生成的证明具有恒定的证明大小(约400字节)和验证时间(约6毫秒),但仍需要通用的可信设置。相比之下,Stark不需要可信设置,但其证明大小(约80KB)和验证时间(约10毫秒)欠佳,并且会随着环路大小而增加。其他系统也各有利弊。在这些证明系统间进行权衡结果将导致计算量的“重心”发生变化。
具体来讲,现在的证明系统通常可以描述为PIOP(多项式交互预言证明)+PCS(多项式承诺方案)。前者可被视为是证明者用来说服验证者的约定程序,而后者使用数学方法确保该程序不会遭到破坏。这好比PCS是枪,而PIOP是子弹。项目方可以按需修改PIOP,且可以在不同PCS中进行选择。
Paradigm的Georgios Konstantopoulos在他关于硬件加速的报告中解释说,生成证明所需的时间主要取决于两类计算任务:MSM(多标量乘算法)和FFT(快速傅里叶变换)。但是,不使用固定参数,而是建立不同PIOP,并从不同PCS中进行选择,将会带来FFT或MSM的不同计算量。以Stark为例,Stark使用的PCS是FRI(快速里德-所罗门码接近性交互预言证明),它基于里所码,而非KZG或IPA使用的椭圆曲线,因此在整个证明生成过程中完全不涉及MSM。我们在下表中对不同证明系统计算量进行了粗略排序,需要注意的是1)很难估计整个系统的确切计算量;2)项目方在执行时通常会按需修改系统。
不同证明系统的计算量
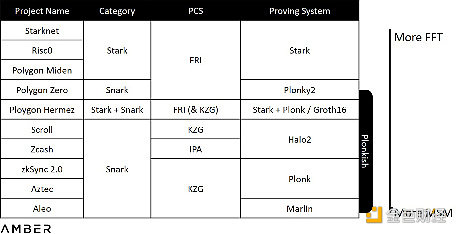
上述情况将使项目方有各自的硬件类型偏好。目前由于GPU(图形处理器)供应量大且便于开发,GPU的使用最广泛。此外,GPU的多核结构非常便于并行MSM计算。然而,FPGA(现场可编程门阵列)可能更擅长处理FFT,我们将在第二部分中详述。如Starknet和Hermez等使用Stark的项目,可能更需要FPGA。
上述得出的另一个结论是,这项技术仍处于早期阶段,缺乏标准化或主导的解决方案。而全面使用特定算法专用的ASIC(专用集成电路)也可能为时过早。因此,开发人员正在探索一个中间地带,我们稍后也会对此做进一步解释。
2.2 趋势与新范式
2.2.1更复杂的陈述
借鉴开篇列出的用例,我们期待零知识在加密行业和现实世界中有更多用途,并实现更复杂的证明,有些甚至可以不必遵守目前的证明系统。项目方可以不采用PIOP和PCS,而是开发最适合自己的新原语。而在如MPC(安全多方计算)的其他领域,在部分工作中采用零知识协议将大大提高其实用性。以太坊最近也为了实现Proto-Danksharding而计划举办KZG可信设置仪式,未来准备进一步实现完整版的Danksharding,以此来处理数据可用性采样。即便是Optimistic Rollup也有可能在未来采用ZKP来提升安全性和缩短争议处理时间。
虽然许多人可能将零知识视为广义加密行业中的一个独立板块,但我们认为应该将零知识视为一种解决行业多个痛点的技术。 反过来看,为了向不同系统和客户提供服务,未来更需要硬件加速具有灵活性和通用性。
2.2.2 本地生成证明
用于保护隐私的ZKP和用于压缩信息的ZKP在结构上有明显差异。为了隐藏交易细节,在证明过程中会涉及一些随机数。用户需要在本地生成证明,但大多数用户没有先进的硬件。更糟糕的是,如果大多数dapp仍然是Web APP,则需要在浏览器中生成证明,这将需要更长的证明时间。例如,当Manta试图为WASM构建高性能证明者时,他们很快意识到“与本地处理速度相比,WASM给用户造成10-15倍的性能损失”。为了解决这个问题,Manta选择成为ZPrize的赞助商和架构师,ZPrize是最大的ZKP加速竞赛之一,并且Manta设置了一个WASM加速专属赛道。提供客户端版本是这类dapp的一个简单解决方案,但需要下载可能会造成部分潜在用户流失,并且客户端也不适用于当前的扩展钱包或其他工具。
另一种解决方案是部分外包证明生成。Pratyush Mishra在第七届零知识峰会期间介绍了这种方法。首先用户执行部分轻量级计算,然后向数个第三方发送公开陈述和加密见证,这些第三方将接着完成剩余证明。按照这种方式,只要其中一方诚实,用户的隐私就不会被泄露。这种方法结合了零知识协议和MPC使用的一些工具。或者,用户也可以利用带宽进行计算:首先生成一个大数据量证明,然后将其发送给第三方,第三方会对证明进行压缩并将其发布到链上。
外包证明生成
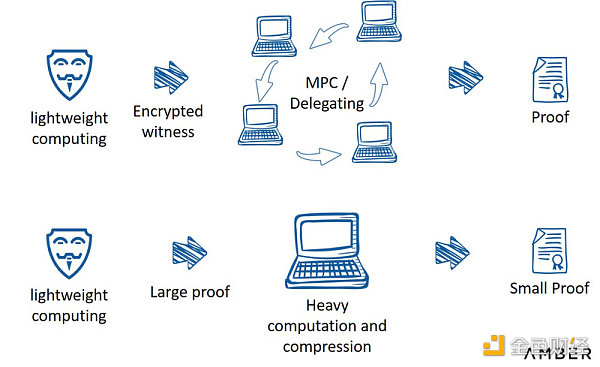
来源:第七届零知识峰会,由Aleo的Pratyush Mishra提出
2.3 与PoW挖矿相比较
虽然人们会很自然地认为ZKP是PoW的一种新颖形式,并将加速硬件视为一种新型矿机,但ZKP生成在目的和市场结构上与PoW挖矿有着本质区别。
2.3.1功率竞争与效用计算
为了赚取出块奖励和交易费用,比特币矿工通过不断迭代随机数来寻找足够小的哈希值,这实际上只与共识的达成相关。与此相比,ZKP生成是实现信息压缩或隐私保护等实际效用的必要过程,而不需要对共识负责。这种区别会影响ZKP潜在的广泛参与性和奖励分配模式。下面我们列出了三种现有设计,来阐述矿工将如何协调ZKP生成。
-
Rates-are-Odds (Aleo): Aleo的经济模型设计是最接近比特币和其他PoW协议的。它的共识机制PoSW(简洁工作证明)仍要求矿工找到一个有效的随机值,但验证过程主要以反复生成SNARK证明为主,该证明以随机值和状态根的哈希值作为输入部分,过程直到某轮生成的证明哈希值足够小为止。我们将这种类似PoW的机制称为Rates-are-Odds模型,因为在单位时间内可以处理的验证数量大致决定了获得奖励的概率。在此模型中,矿工通过囤积大量计算机器来提高获得奖励的机率。
-
Winner-Dominates( Polygon Hermez): Polygon Hermez采用更简单的模型。根据他们公开文档的内容来看,两个主要参与者是排序者和聚合者,排序者收集所有交易并将它们预处理为新的L2批次,聚合者明确其验证意图并竞争生成证明。对于给定的批次,第一个提交证明的聚合者将赚取到排序者支付的费用。在不考虑地理分布、网络状况和验证策略的前提下,拥有最先进的配置和硬件的聚合者可能会占主导地位。
-
Party-Thresholds (Scroll): Scroll将他们的设计描述为“Layer2证明外包”,质押一定数量加密货币的矿工将会被任意选择生成证明。被选中的矿工需要在规定时间内提交证明,否则其下一个epoch的选中概率将被下调。生成错误的证明将会导致罚金。起初,Scroll可能会与十几个矿工合作以提高其稳定性,甚至还会运行自有GPU。而随着时间的推移,他们计划分散整个过程。我们将这个实施分散的时间节点作为参数来衡量Scroll在效率和去中心化之间的重心调整。Starkware也可能属于此类。从长远来看,只有拥有能够及时完成证明的机器才能参与证明生成。
这些协调设计各有不同的侧重点。我们预计Aleo将拥有最高的去中心化,Hermez将拥有最高的效率,而Scroll将拥有最低的参与门槛。 但根据上述设计,零知识的硬件军备竞赛不大可能会马上发生。
2.3.2 静态算法与进化算法
另一个区别是比特币是基于单一的、相对静态的算法。比特币的核心开发者始终尝试遵循初始的设计与精神,以此保持网络稳定并避免严重分叉。而新兴的区块链或项目没有这样的历史遗留限制,这使他们能更灵活地调整系统和算法。
我们认为,与结构简单且呈现静态的PoW市场相比,ZKP的差异性促成了一个更加分散且呈动态的市场结构。我们建议将ZKP生成视为一种服务(一些初创公司将其命名为ZK-as-a-Service),ZKP生成是为达到目的而使用的手段,而非最终目的。这种新范式最终将形成新的业务或收入模式,我们将在最后一节中对此详述。在此之前,我们先来看看多种解决方案。
3. 解决方案
CPU(中央处理器)是通用计算机中的主芯片,在主板上负责给各个组件分发指令。但是,由于CPU旨在快速处理多种任务,这反而限制了处理速度,因此在处理并发或某些特定任务时,通常使用GPU、FPGA和ASIC作为辅助。在本节中,我们将重点介绍它们的特性、优化过程、现状和市场。
3.1 GPU:目前最常用的硬件
GPU最初设计用来操控计算机图形和处理图像,但它的并行结构使其在计算机视觉、自然语言处理、超级计算以及PoW挖矿等领域成为不错的选择。GPU可以加速MSM和FFT,特别是对于MSM,通过利用被称为“pippenger”的算法,开发GPU的过程比FPGA或ASIC要简单得多。
在GPU上加速的理念非常简单:将这些需要算力的任务从CPU转移到GPU。工程师们会将这些部分重写进CUDA或OpenCL,CUDA是一个由英伟达开发用于在英伟达GPU上进行通用计算的并行计算平台和编程模型,CUDA的竞争对手是由Apple和Khronos Group为异构计算提供标准而打造的OpenCL,这使得用户不再被局限于英伟达的GPU。这些代码之后会被编译并可直接在GPU上运行。对于更进一步的加速,抛开改进算法本身,开发人员还可以:
(1) 为降低数据传输成本(尤其是CPU和GPU之间的数据传输),通过尽可能多使用快速存储和少使用慢速存储来优化内存。
(2) 为提高硬件利用率,使硬件尽可能满负荷工作,通过更好地平衡多处理器之间的工作、构建多核并发以及为任务合理分配资源来优化执行配置。
简而言之,我们要尽其所能来并行化整个工作过程。同时应尽可能避免后项依赖前项结果这样的顺序化执行过程。
通过并行化节省时间
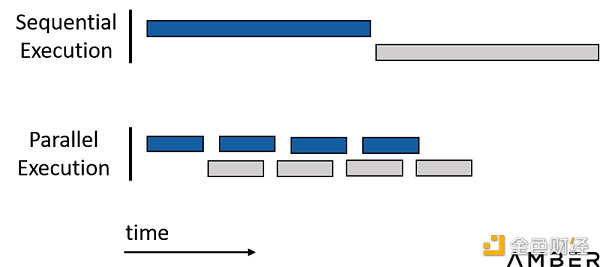
GPU加速设计流程

3.1.1 庞大的开发者群体和开发的便利性
与FPGA和ASIC不同,GPU开发不涉及硬件设计。CUDA或OpenCL也有庞大的开发者群体。开发人员能够基于开源代码快速建立自己的修改版本。例如,Filecoin早在2020年就发布了首个搭配GPU的网络。Supranational最近也开源了他们的通用加速解决方案,目前这可能是同类中最好的开源解决方案。
当考虑除MSM和FFT之外的工作时,这种优势更加明显。证明生成的确主要由这两项主导,但其他部分仍占约20%(来源:Sin7Y的白皮书),因此仅加速MSM和FFT对缩短证明时间作用有限。即使将这两项的计算时间压缩到瞬时,所花费的总时间仍只是最初的五分之一。此外,由于这是一个新兴且不断发展的框架,因此很难预测该比率在未来将如何变化。鉴于FPGA需要重新配置,而ASIC也可能需要重新设计生产,GPU更便于加速异构计算工作。
3.1.2 过剩的GPU
英伟达主导了GPU市场。根据Jon Peddie Research的数据,2022年第一季度英伟达独立GPU出货量占市场份额为78%。尽管许多显卡价格明显高于MSRP(制造商建议零售价),但显卡的供货量还在不断提高。2021年,GPU出货量超过5,000万个(价值520亿美元)。从这个数字来看,这几乎是同期FPGA销量的8.5倍。
GPU芯片市场份额
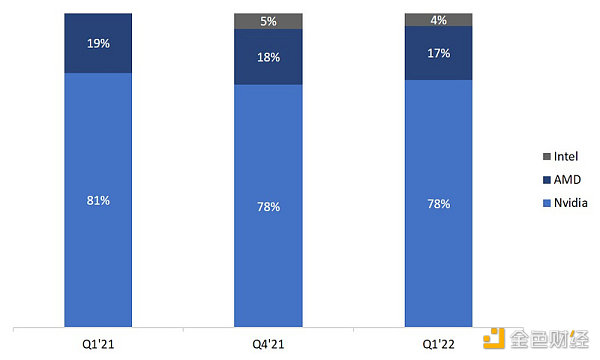
来源:Jon Peddie Research
特别是对于挖矿,我们保守估计在以太坊合并后,大约有626万GPU将从以太坊PoW挖矿中解放出来。假设以太坊哈希率的绝大部分来自GPU,我们将以太坊当前的哈希率(890 Th/s)乘以90%,再用得到的数字(801 Th/s)除以最先进的GPU显卡RTX 3090 Ti的挖掘能力(128 Mh/s),这样就能得出我们保守估计的GPU数为626万个。由于ASIC主导比特币挖矿,也没有其他使用PoW的项目可以容纳这么大的闲置挖矿能力,因此除了挖掘以太坊分叉或提供云服务外,这些即将闲置的GPU转向零知识证明服务是值得探索的选择。
以太坊哈希率
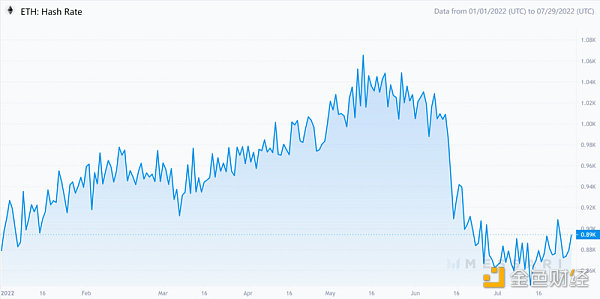
来源:Messari
3.2 FPGA:平衡成本与效率
FPGA是具有可编程结构的集成电路。因为FPGA芯片内部的电路未经过硬蚀刻,因此设计人员可以根据特定需求对其进行多次重新编程。一方面,这有效地削减了ASIC的高额制造成本。另一方面,其硬件资源的使用比GPU更灵活,使得FPGA有进一步加速和省电的潜力。例如,尽管可以实现在GPU上优化FFT,但频繁地打乱数据会导致GPU和CPU之间的数据传输量很大。然而,打乱并不是完全随机的,通过将内在逻辑直接编写到电路设计中,FPGA有望更快地执行任务。
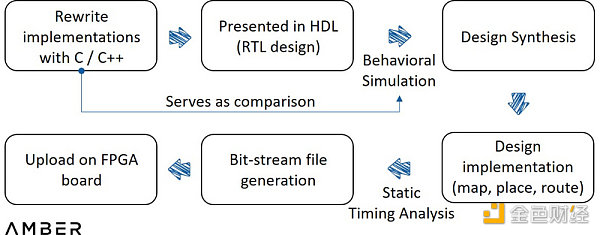
要在FPGA上实现ZKP加速,仍然需要几个步骤。首先,需要一个用C/C++编写的特定证明系统的参考实现。然后,为了在更高层次上描述数字逻辑电路,这个实现需要用HDL(硬件描述语言)来描述。
随后需要通过模拟调试来显示输入和输出的波形,以此查看代码是否按预期运行。这一步是涉及实现最多的步骤。工程师不需要整个过程,而只需通过比较这两个输出就能识别一些微小错误。然后,合成器会将HDL转换为具有门和触发器等元件的实际电路设计,再将设计应用到设备架构和更多模拟分析上。一旦确认电路能够正常运行,最后将创建一个编程文件并将其加载到FPGA器件中。
FPGA设计流程
3.2.1当前的障碍和尚未完备的基础设施
虽然可以重复利用GPU上的一些模块优化工作,但也面临一些新的挑战:
(1) 为了内存安全性更高且跨平台兼容性更好,长期以来零知识的开源实现大多是用Rust编写的,但大多数FPGA开发工具都是用硬件工程师更为熟悉的C/C++编写的。在实施之前,团队可能必须重写或编译这些实现。
(2) 在编写这些实现时,软件工程师只能在范围有限的C/C++开源库中选择代码,这些库可以通过现有的开发支持映射到硬件架构中。
(3) 除了软件工程师和硬件工程师可以分别独立完成的工作之外,还需要他们的密切协作来完成一些深度优化。例如,对算法的一些修改会大量节省硬件资源,同时保证其发挥与之前相同的作用,但这种优化基于对软硬件的理解。
简而言之,与AI或其他成熟领域不同,工程师必须从零开始学习和构建以实现ZKP加速。幸运的是,我们看到了更多进展。例如,Ingonyama在他们最近的论文中提出了PipeMSM,这是一种在FPGA或ASIC上加速MSM的方法。
3.2.2 双头垄断市场
FPGA市场是典型的双头垄断市场。根据Frost & Sullivan 的数据,Xilinx(2022年2月被AMD收购)和Altera(2015年12月被英特尔收购)在2019年全球FPGA市场出货量中合计占比约85%。想要尽早使用最先进的FPGA可能需要与英特尔或AMD建立密切关系。此外,零知识作为新兴领域已经引起了行业巨头的注意。AMD是ZPrize的技术提供商之一。
FPGA市场是典型的双头垄断市场
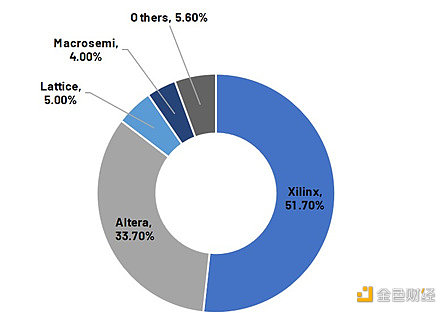
来源:Frost & Sullivan
工程师们已经意识到,单个FPGA无法为复杂的ZKP生成提供足够的硬件资源,因此必须同时使用多卡进行验证。即使有完备的设计,AWS及其他供应商提供的现有标准FPGA云服务并不理想。此外,提供加速解决方案的初创公司通常规模太小,无法让AWS或其他公司托管他们的定制化硬件,而且他们也没有足够的资源来运行自己的服务器。与大型矿工合作或与Web3原生云服务提供商合作可能是更好的选择。然而,考虑到挖矿公司的内部工程师也可能将开发加速解决方案,这种合作关系可能会很微妙。
3.3 ASIC:终极武器
ASIC是为特定用途专门定制的集成电路(IC)芯片。通常,工程师仍会使用HDL来描述ASIC的逻辑,这种方式类似于使用FPGA,但最终电路会永久地绘制到硅片中,而FPGA中的电路是通过连接数千个可配置模块而制成的。不同于从英伟达、英特尔或AMD采购硬件,公司必须设法自己完成从电路设计到制造和测试的整个过程。ASIC将仅限于某些特定功能,但相反在资源分配和电路设计方面这赋予设计人员最大程度的自由度,因此ASIC在性能和能耗效率方面拥有巨大潜力。设计人员可以在空间、功率和功能上消除浪费,只需根据预期应用来设计确切数量的门,或调整不同模块的大小。
在设计流程方面,与FPGA相比,ASIC需要在HDL的编写和整合这两步之间加入流片前验证(以及DFT),并且实施前需要布图规划。前者是工程师在虚拟环境中使用复杂模拟工具测试设计,后者用于确定芯片中模块的尺寸、形状和位置。设计实现后,所有文件都会被送到台积电或三星等代工厂进行测试流片。如果测试成功,则会将原型送去组装和检测。
ASIC设计流程
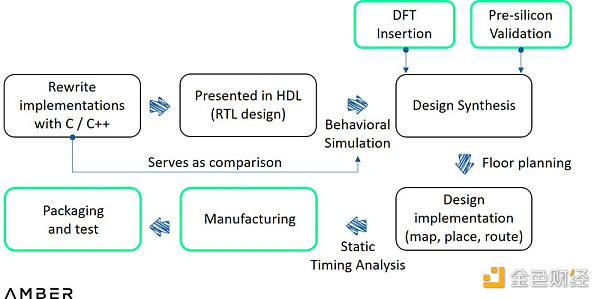
3.3.1 零知识领域相对通用的ASIC
ASIC遭到的一个普遍批评是,一旦算法改变,以前的芯片就完全没用了,但不一定如此。
巧合的是,与我们交流过的所有计划开发ASIC的公司都没有孤注一掷于特定的证明系统或项目。相反他们更喜欢在ASIC上开发一些可编程模块,以便通过这些模块应对不同的证明系统,并且只将MSM和FFT任务分配给ASIC。这对于特定项目的特定芯片来说不是最理想的,但是在短期内比起用于特定任务的设计,牺牲性能来获得更好的通用性可能是更优的选择。
3.3.1 昂贵但非经常性的成本投入
不仅ASIC的设计过程比FPGA复杂得多,而且制造过程也会消耗更多的时间和金钱。初创公司可以直接联系代工厂进行流片或通过分销商。到真正能够开始执行可能需要等待大约三个月或更长时间。流片的主要成本来自于掩模版和晶圆。掩模版用于在晶圆上形成图形,晶圆是一片薄硅片。初创公司通常选择MPW(多项目晶圆),可以与其他项目方共同分担掩模版和晶圆的制造成本。但是,取决于他们选择的工艺和芯片数量,保守估计流片成本仍将高达数百万美元。流片以及组装和测试还需要几个月的时间。如果可行,才终于能够开始准备量产。但是,如果测试出现任何问题,调试和故障分析又将花费难以估计的时间,并且需要再次流片。从最初的设计到量产需要几千万的资金,还需要大约18个月的时间。得以慰藉的是,上述成本的很大一部分属于非经常性成本。此外,ASIC拥有高性能且能够节省能源和空间,这都是很重要的,并且价格可能相对较低。
4.结语
下面我们对不同硬件解决方案进行了一般性评估。
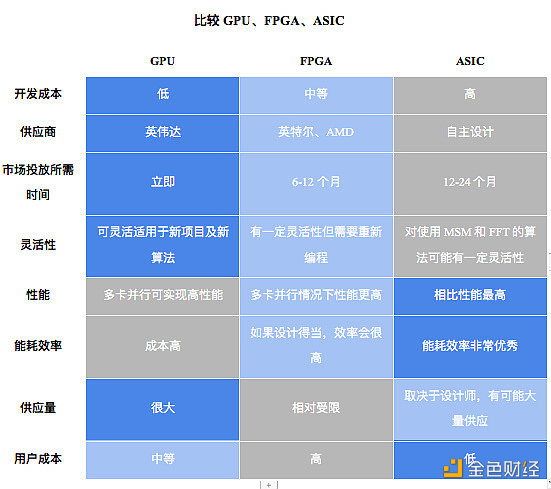
来源:Amber
为了更直观地了解可用商业模式,我们在如下图表中展示了所有潜在的市场参与者。由于参与者之间可能存在交叉关系或者复杂情况,因此我们仅按功能对他们进行分类。
硬件加速的功能层
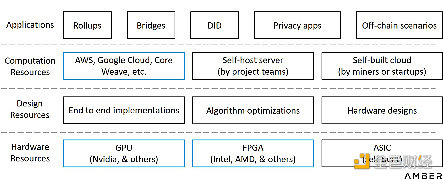
除了开发GPU或FPGA芯片外,初创公司还可以从上述任何功能层进入零知识领域。可以选择从零开始设计和制造ASIC,并将芯片封装成专用设备卖给矿工,或者可以将裸芯片卖给下游供应商组装。初创公司还可以选择自建服务器,参与证明生成或提供云服务。或者,也可以选择成为咨询公司,提供设计解决方案,但不参与实际操作。如果公司拥有强大的合作伙伴关系或足以覆盖整个价值链的资源,那么还可以为零知识应用程序提供从硬件资源到定制化系统设计的全栈解决方案。
零知识尚未实现大规模应用,构建加速解决方案也将是一个漫长的过程。我们拭目以待未来的转折点。对于构建者和投资者来说,关键问题是这个转折点何时到来。
致谢
特别感谢Weikeng Chen(DZK)、Ye Zhang(Scroll)、Kelly(Supranational)和Omer(Ingonyama)帮助我们理解所有技术细节。还要感谢Kai(ZKMatrix)、Slobodan(Ponos)、Elias和Chris(Inaccel)、Heqing Hong(Accseal)和许多其他人对本研究提供见解。
来源:Amber Group、星球日报

Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
Justin Sun suspected to have purchased $160m in Ethereum
Justin Sun suspected to have purchased $160m in Ethereum