万字长文深度剖析:构建去中心化网络有哪些具体挑战?



本文转自公号:老雅痞
作者:Eric Rescorla
最近,人们对通常被称为去中心化网络(dWeb)的东西很感兴趣(尽管现在我们听到更多的是Web3这个词)。勾勒出这些术语之间的确切区别(假设这是有可能的)不在这篇文章的讨论范围之内(尽管Web3似乎在某种程度上涉及到区块链),但这里的共同点似乎是用一个不太中心化的网络生态系统来取代现有的相当中心化的网络生态系统。这篇文章探讨了实际建立这样一个系统所面临的挑战。
网络的基础设施至少在两个主要方面是中心化的:
-
面向用户的主要内容分发平台相对较少(Google、YouTube、Facebook、Twitter、TikTok等),它们显然对网民传播信息的能力具有巨大的影响力。
-
即使你愿意放弃在这些内容平台上发布信息,建立任何大规模系统的最简单方法(几乎是唯一经济的方法,除非你的资金非常充足)是在相对较少的基础设施供应商之一中运行,如亚马逊AWS、谷歌云平台、Cloudflare、Fastly等,他们已经拥有高度可扩展的地理分布系统。
在这种情况下,去中心化可以意味着从建立那些以不太中心化的方式运作的特定内容平台的类似物(如Mastodon或Diaspora)到在IPFS或Beaker这样的点对点平台上重建整个网络的结构。自然,在第二种情况下,你也会想让这些内容平台有可能只是更好重现!使用一个大部分或完全的点对点系统至少不应该要求在某个地方有一堆大的服务器来使这一切运作。这第二个更加雄心勃勃的项目是这篇文章的主题。
分布式与去中心化的区别
这里要做的一个重要区分是分布式系统(通常也称为联合式)和去中心化系统(通常称为点对点)之间的区别。举个例子,网络是一个分布式系统:它由许多不同的网站组成,由不同的实体运营,但这些网站是在服务器上运行的,运营一个网站需要自己运行一个服务器或将其外包给其他人。这些服务器必须准备好处理所有用户的负载,这意味着它们必须在某个地方有大量的带宽,当更多的用户试图连接时,可以优雅地扩展,等等。
相比之下,BitTorrent是一个去中心化的系统: 它使用BitTorrent用户本身的资源来提供数据,这意味着你不需要一个巨大的服务器来发布数据到BitTorrent网络,即使有很多人想下载它。 即使在带宽便宜的世界里,这也有一些明显的操作优势,但特别是如果你想发布一些别人不愿意发布的东西,也许是因为政府的审查制度或更经常的版权原因。如果你运行一个服务器,你很难隐瞒有一百万人刚刚连接下载了某部电影,你应该担心版权警察来找你,但如果你只是把你的拷贝发布到BitTorrent网络中,要想知道是谁发布的就难多了,特别是如果其他50人也这样做的话。
请注意,有可能出现基本上是去中心化的混合系统(但它却依赖于中心化的组件)。例如,在点对点系统中,新的对等节点通常需要连接到一些“引入服务器”来帮助他们加入网络;这些服务器需要易于查找,并且要做到这一点,一种(尽管不是唯一的)方法就是中心化操作它们。
从历史上看,点对点系统已经在相对有限的领域进行了部署,主要是那些与上述抵制审查的用例之外的某种部署有关。 然而,人们对更广泛的用例当然有很多兴趣,包括取代网络的大部分内容。这是一个非常困难的问题,部分原因是这种系统在本质上不如中心化或联合式的系统有效和灵活。这篇文章探讨了建立这样一个系统所面临的挑战。这并不是说以更多的联盟方式建立像Twitter或Facebook这样的系统就没有挑战,但问题的规模不同(也许这是另一篇文章的主题)。
点对点架构与客户/服务器架构的对比
与点对点架构相反的是客户/服务器架构,也就是说,在一个系统中,各元素扮演着不对称的角色,其中一个元素(通常属于用户[1])是 “客户”,另一个元素(通常是与某个组织相关的某种共享资源)是 “服务器”。例如,这就是网络的工作方式,客户端是浏览器。相比之下,点对点系统被认为是对称的。
然而,在实践中,这些界限可能是相当模糊的。例如,常见的系统是在客户端和服务器架构之间以及服务器之间使用相同的协议,第二种模式更像是典型的 “点对点 “配置。例如,邮件客户使用SMTP发送电子邮件,但邮件服务器也使用SMTP相互发送电子邮件,发件人承担 “客户”的角色;显然在这种情况下,每个 “服务器 “既是客户又是服务器,取决于邮件流向的方向。即使在名义上是点对点的系统中,也经常使用为客户/服务器应用而设计的协议(如TLS),在这种情况下,即使上述应用是对称的,节点也可能为这些协议的目的承担客户/服务器角色。
点对点系统的基本原理
我们都(希望)知道像网络这样的客户/服务器发布系统是如何工作的,但点对点(以下简称P2P)发布系统是如何工作的呢?让我们从讨论最简单的情况开始,也就是发布不透明的二进制资源(文档、电影,等等)。本节试图描述这样一个系统的足够的基础知识,以便使本篇文章的其余部分有意义。
在客户端/服务器系统中,要发布的资源存储在服务器上,但在P2P系统中,没有服务器,所以资源存储在 “网络中”。 这在操作上的意思是,它存储在碰巧此时在线的用户的某个子集的电脑上。为了使其发挥作用,我们需要一套规则(即协议)来描述哪些端点存储了特定的内容,以及当你想检索它时如何找到它们。一个常见的设计是所谓的分布式哈希表,这基本上很抽象,其中每个资源都有一个 “键”(即一个地址),用来引用它,还有一个 “值”,是其实际内容。密钥决定了哪个(些)节点负责存储该值,并被其他节点用来存储和/或检索它。
作为一个直观的疑问,请考虑下面的DHT系统。这是Chord(在计算中,Chord是一种点对点分布式哈希表的协议和算法。分布式哈希表通过将键分配给不同的计算机称为“节点”来存储键值对;一个节点将存储它负责的所有键的值。Chord 指定如何将键分配给节点,以及节点如何通过首先定位负责该键的节点来发现给定键的值。Chord 是与CAN、Tapestry和Pastry一起的四种原始分布式哈希表协议之一)的过度简化版本,它是最早的 DHT 之一,所以我们称它为“Note”。注意,系统中的每个节点都有一个随机生成的标识符,它是一个来自0至 2∧256 -1的数字(抱歉读者们,我们用了LaTeX 表示法)。通常我们认为这些数字被组织成了一个环,ids 是顺时针分配的,因此节点2∧256 -1 就在(之前)节点0旁边,如下图所示:
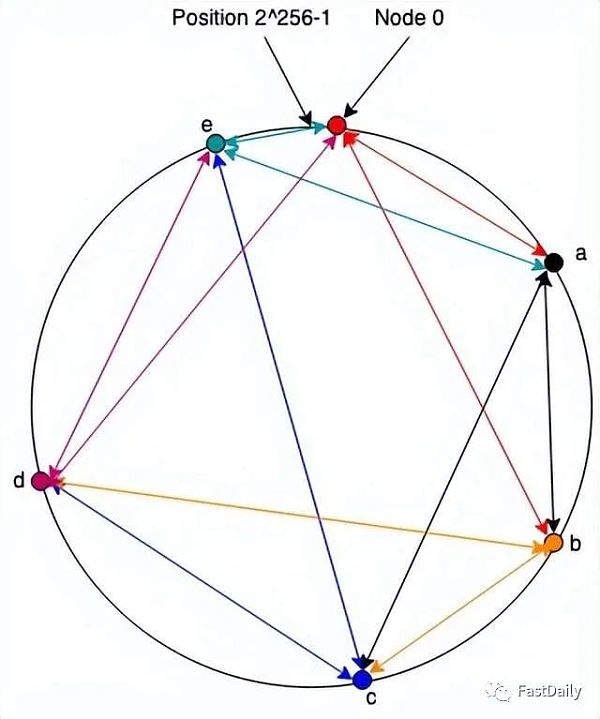
网络中的每个节点(”环”)都保持着一组与环中其他节点的连接(箭头的颜色是根据保持连接的节点而定)。我不会在这里详细介绍这些算法,只想说让这些算法有效地工作是制作DHT的科学的重要内容。在注释中,我们只假设每个节点都与下一个节点(即具有下一个最高身份的节点)和其他更远的节点有一个连接,如上图所示。
为了与具有 id 的节点通信?, 一个节点向它所连接的节点发送一条消息?,并带有 id?最接近但不大于,(即,如果你顺时针绕圈,你连接到的节点不会位于它们之间)。节点?做同样的事情。当你最终到达一个直接连接到的节点?时,它传递消息。例如,如果节点0想向节点 c发送一条消息,它将把它发送给b,然后 b 将它发送给c。当c想要回复时,它将它发送给连接到节点0的节点e ,因此直接发送它。请注意,这意味着请求/响应对需要围绕环进行整个行程。
存储数据
到目前为止,我们只有一个通信系统,但是(相对)容易把它变成一个存储系统:我们在与节点标识符相同的命名空间中为每条数据分配一个地址,并且每个节点负责存储任何数据(位于它和前一个节点之间的地址)。因此,例如,在下图中,节点c将负责存储地址为k的资源,节点e将负责存储地址为l的资源。
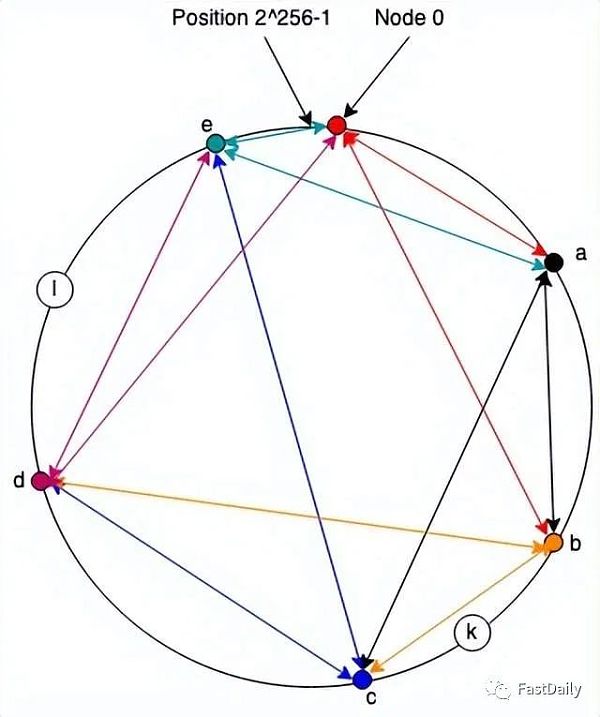
如果节点a想要存储地址为k的值,它会向c 发送一条消息,要求存储它。同样,如果节点d想要检索它,它会向c发送一条消息。
当然,这里有几个明显的问题。 首先,如果节点c从网络上掉下来会怎样? 毕竟,它是某人的个人电脑,所以他们随时都可能关闭它。这个问题的答案自然是将数据复制到其他一些节点上,这样一来,这些节点同时下线的概率就会适当降低。精确的复制策略也是一个复杂的话题,根据DHT的不同而不同,我们不需要在这里讨论它。
第二,如果某个值既大又流行怎么办? 在这种情况下,存储它的节点可能突然要一次性传输大量的数据。这很容易使某人的链接完全饱和,即使他们有一个快速的互联网连接。唯一真正的解决办法是分配负载,你可以通过两种方式做到。首先,你可以将资源分块(例如,将你的电影分成5分钟的小块),然后将每个分块存储在不同的地址下;这样做的影响是,不同的节点将负责发送每个小块,因此它们的带宽份额也相应地减少。你也可以尝试让更多的节点负责流行的内容,这也会分散负载。
最后,如果每条信息都要穿越几个节点才能被送达,这就会增加网络的总负载,与路径长度(节点数量)成正比,同时也会因为延迟而降低性能。 处理这个问题的方法之一是让两个通信节点建立一个直接的连接来进行大量的数据传输,并使用DHT来取得联系,这样他们就可以做到这一点。这就大大降低了整体负荷。
命名事物
在前面的描述中,我已经交待了事物的地址是如何得出的。
一种常见的设计是通过对象的内容来计算地址,例如通过散列。 这就是所谓的内容可寻址存储(CAS),在很多情况下很方便,因为它不需要DHT中的任何额外内容完整性。如果你知道该对象的哈希值,你就可以检索它,如果哈希值出现错误,你就知道检索它时出现了问题。
当然,考虑到你需要对象来计算它的哈希值,这种设计意味着你需要一些服务来把你知道名字的对象(例如,”John Wick”)映射到它们的哈希值上,所以现在我们要么有一个中心化的服务来做这个,要么我们需要建立一个点对点版本的服务,我们又回到了我们开始的地方。
另一种常见的方法是拥有从加密密钥衍生出来的名字。 例如,我们可以说,我的所有数据都存储在我的公钥的哈希值上(同样,也许有一些合适的分片系统)。当数据被存储时,我们会要求它被签名,节点会丢弃那些签名没有被验证的存储值。这有很多优点,但其中一个关键的优点是,你可以让给定地址的数据发生变化,因为地址与加密密钥而不是内容相联系。例如,假设被存储的是我的网站;我可能想改变它而不想发布一个新的地址。有了与密钥绑定的地址,这是可能的。
显然,加密钥匙也不是很好的标识符,因为它们很难被记住,但据推测,你会在上面设置某种去中心化的命名层,例如基于区块链的命名层。
安全
任何真正的系统都需要某种方式来确保内容的完整性。与网络不同,仅仅建立一个与存储节点的TLS连接是不够的,因为那只是某人的计算机,它可能会说谎(尽管你仍然可能想出于隐私原因而说谎)。相反,每个对象需要以某种方式进行完整性保护,要么让它的地址成为它的哈希值,要么通过数字签名。
除了内容的完整性之外,这里还有很多地方可能出错。例如,如果负责的节点声称一个给定的对象(或一个你试图路由到的节点)不存在,会发生什么?或者,如果一组节点试图通过DDoS攻击使网络流量饱和怎么办?你如何处理人们试图存储或检索超过其 “公平份额”(不管那是什么)的数据。人们谈论了各种方法来解决这些问题,但我们对DHT的操作经验比我们对网络的操作经验规模要小,而且对故障的容忍度要高得多(如果人们突然无法从BitTorrent下载《冰雪奇缘》,迪士尼就不会损失很多钱),所以不清楚它们是否能在规模上真正安全。
一个去中心化的网络发布系统
现在我们有了一种存储数据并再次找到它的方法,我们有了一个开始,可以想象如何建立一个去中心化的网络版本。就像我们在研究网络如何工作时一样,让我们从发布静态文件开始。
回顾一下URI的结构:

我们需要做的是把这个结构映射到我们的P2P存储系统的资源上。因此,我们最终可能会得到一个像下面这样的URL:

起源
这个系统的一个重要的安全要求是,与不同机构相关的数据有不同的起源(背景见这里:
https://educatedguesswork.org/posts/web-security-model-origin/)。如果多个用户发布的数据有不同的起源,那么他们可以通过浏览器互相攻击,这是一个明显的问题。
note: 一开始就告诉我们需要使用 Note 而不是通过 HTTP 来检索数据。在中间部分,我们没有一个“host”字段告诉我们从哪里检索普通 HTTPS URI 中的内容,而是有一个“authority”字段,它告诉我们将使用其密钥的用户的身份对 URL 的数据进行签名。如上所述,我假设我们有一些方法可以将用户友好的身份映射到键;有些系统没有,这似乎对用户很不利,但如果你愿意,可以随意将权限视为密钥哈希。
资源本身被存储在一个由Hash(URL)给出的地址上(这是对我上面描述的一个小而简单的改变),并且如上所述,由与权威相关的密钥签名。
如果你首先假设P2P系统的存在,这一切都很简单。为了发布一些东西,我在DHT中的URL地址处做了一个存储,并用我的密钥签名。然后我就可以把这个URL交给人们,他们可以通过计算地址,然后验证签名的资源,从DHT中检索数据。请注意,由于地址是从URL而不是从内容中计算出来的,因此只需做一个新的存储,就可以就地更新。
退一步说,这确实有点像我上面描述的价值主张:任何人都可以将网站发布到网络上,而不需要有一屋子的电脑,也不需要支付亚马逊/谷歌/Fastly等。因此,如果你不仔细看,它似乎是完成了任务,很容易理解这种热情。不幸的是,这个系统也有一些相当严重的缺点。
性能
性能(这里指的是页面加载的时间)是网络浏览器和服务器的一个主要考虑因素。对网络性能最重要的是检索每个资源所需的时间。这与视频会议或游戏不同,在视频会议或游戏中,延迟(你的数据包到达对方的时间)或抖动(延迟的变化)真的很重要。在网络中,这主要是指下载速度。
连接
为了理解从客户/服务器到点对点的转变对性能的影响,有必要了解一下网络和数据传输的工作原理。互联网是一个分组交换的网络,这意味着它传输的是1000字节左右的单独寻址的信息。由于网络资源通常大于1K,客户和服务器通过建立连接来传输数据,连接是双方的持久联系,它将一组数据包映射成每一方都可以读写的数据流的样子。发送方将文件分解成数据包并发送,接收方负责在收到后重新组装。历史上这是由TCP完成的,尽管现在看到越来越多的人使用QUIC,它的操作原理类似,至少在我们需要在这里讨论的层面上是这样的。
下图显示了一个使用TCP和TLS 1.3安全的HTTPS连接的开始:

增加一个连接上的HTTP请求的数量
当HTTP最初被设计时,你只能在一个连接上有一个请求。由于我在这里描述的原因,这是非常低效的,而且在很大程度上由于Jeff Mogul的工作,增加了一个功能,允许在同一个连接上发出多个请求。不幸的是,这些请求只能连续发出,这就造成了一个新的瓶颈。作为回应,浏览器开始在同一个网站上创建多个并行连接,这让他们可以一次发出多个请求(由于TCP动态,有时也会抢占更大一部分的可用带宽)。2015年,HTTP/2增加了在同一TCP连接上复用多个请求的能力,响应交错进行,但仍有一个问题,即响应A的数据包丢失后,其他所有的响应都会停滞(这种特性称为线头阻塞),这在多个连接之间不会发生。最后,2021年发布的QUIC增加了多路复用功能,即使在单一的QUIC连接上也没有线头阻塞。
正如你所看到的,前两次往返完全是为了建立连接而消耗的。在两次往返之后,客户端终于可以请求资源了,在最终获得任何数据之前又是一次往返。根据网络细节,每次往返的时间可能从几毫秒到200毫秒不等,因此,在浏览器看到第一个字节的数据之前,可能需要600毫秒。这是一个大问题,在过去的几年里,IETF已经花费了相当大的努力来减少网络连接建立时间的往返次数(使用TLS 1.3和QUIC)。
一旦建立了连接,你就需要传递数据,这并不是一下子就能完成的。正如我之前提到的,它被分解成一个个数据包流,随着时间的推移被发送到另一边。这就是事情变得有点棘手的地方,因为发送方和接收方都不知道网络的容量(即,它能承载多少比特/秒),如果发送方试图发送得太快,那么额外的数据包就会被丢弃。为了避免这种情况,TCP(或QUIC)试图通过逐步加快发送速度来计算出一个安全的发送速率,直到出现拥堵的迹象(例如,数据包丢失或延迟),然后再退缩。重要的是,这意味着最初你不会使用网络的全部容量,直到连接变暖(这被称为 “慢速启动”),所以数据传输率往往会随着时间的推移越来越快,直到达到稳定状态。
所有这一切的含义是,新的连接是昂贵的,你想通过一个连接发送尽可能多的数据。事实上,在过去的30年里,HTTP的大部分发展都是在寻找方法,使单个网页使用越来越少的连接。
点对点的性能
这就把我们带到了点对点系统的性能问题上。正如我上面提到的,如果你想移动大量的数据,你真的想让客户端直接连接到存储数据的节点上。这带来了几个问题。
首先,我们有通过P2P网络发送第一条信息的延迟,然后再返回。这通常会比直接信息慢,因为它不能采取直接路径。然后,一般来说,不可能简单地直接与其他人的个人电脑建立连接,因为他们通常在NAT和防火墙等网络元素后面。所谓的 “打洞 “协议,如ICE,在许多情况下允许你建立直接连接,但它们会引入额外的延迟(至少一个往返,但往往更多)。一旦完成,你还必须建立一个加密连接,所以我们说的是额外的2次往返的地方。更糟糕的是,在很多情况下,存储节点在拓扑上离你很远,因此有很长的往返时间;大网站和CDN故意把存在点设在靠近用户的地方,但这对P2P系统来说是个更难的问题。当然,即使连接已经建立,我们仍然处于缓慢启动状态。
这对网站来说都有点不合适,因为网站往往由大量的小文件组成。例如,谷歌的主页通常被设计成轻量级的,目前由36个独立的资源组成,其中最大的是811KB。如果这些资源中的每一个都单独存储在DHT中,那么你将会经常运行协议的低效设置阶段,而几乎不会进入高效的数据传输阶段。这与HTTP和QUIC形成鲜明对比,它们试图保持与服务器的连接开放,从而可以摊薄启动阶段的费用。
显然,把网站上的一些资源捆绑到一个单一的对象中是可能的,但这也有其他问题。首先,这对浏览器的缓存很不利,因为这些对象中有许多会在后续的加载中被重复使用。其次,这使得与单个节点的连接成为下载过程中的限制性步骤,如果该节点(只是记得别人的电脑)没有良好的网络连接或暂时过载,这就很糟糕了。其结果是,我们有一个矛盾,即我们想尽量减少个人的获取延迟,也就是通过一个单一的连接发送所有的东西,而我们想做的是为了避免单一元素的瓶颈,也就是像BitTorrent那样一次从很多服务器上下载。
在像电影下载这样的情况下,所有这些都不是问题,因为对象很大,所以总体吞吐量比延迟更重要。在这种情况下,你可以将你的连接并行化,并保持管道的完整。然而,这并不是网络的情况,人们真正注意到的是页面加载时间。据我所知,建立一个大型的P2P网络,其加载时间的性能与网络相当,这是一个大部分未解决的问题。
安全和隐私
即使我们假设P2P网络本身是安全的,即攻击者无法破坏它,而且数据是经过签名的,这个系统仍然有一些令人担忧的特性。
隐私
在任何像网络这样的系统中,向客户提供数据的节点会了解某个客户对哪些数据感兴趣,至少是客户的IP地址水平。在目前的网络中,这并不是一个理想的情况,因此有了像Tor、VPN、Private Relay等IP地址隐藏技术,但至少它在某种程度上仅限于你选择与之互动的可识别实体(当然,网络广告中无处不在的跟踪使情况相当糟糕)。
P2P系统的情况更糟糕:下载一个内容意味着联系互联网上或多或少的随机计算机,告诉它你想要什么。正如我在上面指出的,你可以通过P2P网络路由所有的流量(但它严重损害隐私),所以现实中你将与该节点共享你的IP地址。更糟糕的是,在大多数情况下,数据将被分散在多个节点上,这意味着很多不同的随机人都会看到你的浏览行为。最后,在许多网络中,节点有可能影响他们所负责的数据,在这种情况下,人们可以想象那些希望进行监视的实体试图对特定种类的敏感数据负责,然后记录谁来检索它;事实上,这似乎已经在BitTorrent中发生了。
访问控制——将公众置于发布中
网络上的大部分内容是向所有人开放的,但也有很常见的情况是,你想限制对某一数据的访问。这可以是网站的数据,如《纽约时报》等网站的付费墙,也可以是用户的数据,如Facebook或Gmail的数据。这些都是以明显的方式实现的,即在服务器上有一个访问控制列表,说明哪些用户可以访问每块数据,并拒绝向未经授权的用户提供数据。然而,这在P2P系统中是行不通的,因为没有服务器来执行:数据只是存储在人们的电脑上,即使网站发布了访问控制规则,网站也不能相信存储节点会遵守这些规则。它甚至可能被攻击者所控制。
这个问题的传统答案是在内容存储到DHT之前对其进行加密。即使DHT中的数据是公开的,那也只是密码文本。当内容是用户的,并且他们不想与任何人分享时,这实际上是适度的工作,因为他们可以将其加密到他们知道的密钥,然后只是将其存储在DHT中。这甚至可以通过现有的API(如WebCrypto)来完成,而密钥则存储在用户的计算机上。如果他们想与其他人分享,效果就会差很多——尤其是像Google Docs这样的读/写应用程序,因为你需要对所有的访问规则进行加密执行机制。在这方面已经有一些真正的工作,如SiRiUS和Tahoe-LAFS的加密文件系统,但这是一个复杂的问题,我不知道任何真正大规模的部署。
付费墙的问题实际上更难。例如,《纽约时报》可以对其所有内容进行加密,然后给每个订阅者一个可以用来解密的密钥,但是考虑到订阅者的数量,而且只要有一个人泄露密钥,[3] 该密钥泄露的可能性基本上是100%。[4] 当然,人们也会分享《纽约时报》的密码,但使这个问题更难的是,该密码必须在《纽约时报》网站上使用,而且有可能检测到不当行为,例如当20人使用同一个密码。我不知道这里有什么真正好的纯P2P解决方案。
非静态内容
访问控制实际上是一个更普遍的问题的特例:许多网站(如果不是大多数的话)不仅仅是简单地发布静态内容,这些网站依赖于服务器端的处理,这在一个分散的系统中是很难复制的。
非秘密计算
作为热身,让我们拿一个相对简单的问题举例,即我在网络安全模型系列第二部分中描述的购物网站。实际上,这个网站有三个需要被复制的服务器端功能。
-
产品搜索
-
购物车维护
-
采购
其中第二和第三项功能实际上是相当直接的:购物车可以完全存储在客户端,或者,如上一节所述,由客户端在P2P系统中自我加密存储。购买这一块可以通过某种加密货币来处理(尽管如果你想使用信用卡,事情就更复杂了)。然而,产品搜索就比较困难了。明显的解决方案是在网络中发布整个产品目录,让客户下载,并在本地进行搜索。这显然有一些相当不理想的性能后果:亚马逊有海量的目录数据,这些数据的变化非常频繁复杂。
显然,这在Web 2.0世界中的工作方式是,服务器只是运行计算并返回结果,在这一点上,你通常会听到有人提出某种分布式计算系统,如 Ethereum 智能合约(尽管你可能不希望结果记录在区块链上)。在这种情况下,网站不是发布一个静态资源,而是发布一个要执行的程序来返回结果(通常这些程序是用WebAssembly编写的)。
除了明显的问题,即这仍然需要执行程序的节点拥有所有的数据,最终用户客户端很难确定该节点是否正确执行了程序。即使在一个简单的案例中,比如搜索匹配的记录:如果这些记录是签名的,那么节点就不能替换他们自己的值,但他们有可能隐藏匹配的值。当然,有一些加密技术有可能使其证明计算是正确的,但它们还远远微不足道。所以,这并没有一个真正伟大的解决方案。
秘密信息
一个购物网站实际上是一个相对简单的案例,因为信息基本上在某些情况下是公开的,网站可能不希望他们的目录是公开的,但有很多情况下,网站想用秘密信息进行计算。这里主要有两种情况:
-
网站的秘密信息,例如Twitter的推荐算法是不公开的。
-
用户的秘密信息,例如他们在约会软件中 “向右滑动 “过的其他用户,甚至只是用户的个人资料细节。
在Web 2.0中,这种工作方式是,服务器知道秘密信息并将其用于计算,但不向用户透露。但是,与搜索案例一样,这并不容易移植到P2P案例中,因为将信息透露给随机的人的个人电脑并不安全。
当然,有用于计算具有加密数据的特定功能的加密机制。例如,Private Set Intersection技术可以确定Alice和Bob是否都互相滑动,并且只告诉他们是否都这样做了,但是它们很复杂,更重要的是特定于任务,因此你需要为每个应用程序提供解决方案,有时这意味着发明新的加密技术(要清楚,这远非实现安全P2P约会系统所需的全部内容!)
这实际上是在 “受信任的 “服务器上进行的计算的加密替换的一个普遍问题。加密方法的积极一面是它们可以提供强大的安全保证,但消极的一面是,基本上每个新的计算任务都需要一些新的加密技术,这使得变化非常缓慢和昂贵。相比之下,如果你在服务器上做计算,那么改变你的计算只是一个编写和加载到服务器上的问题。明显的缺点是,人们必须信任服务器,但显然很多人愿意这样做。
混合架构
有时用于解决此类功能问题的一个想法是拥有混合架构。例如,人们可能会想象通过P2P网络提供目录的静态内容来实现购物网站,但必须拥有一个处理搜索并返回指向目录相关部分的指针的服务器。你甚至可以加密每个单独的目录区块,以便竞争对手很难看到你的整个目录。你甚至可以想象建立一个约会网站!P2P和服务器技术的某种组合,用于确定您可以看到哪些配置文件以及与哪些配置文件匹配的逻辑在服务器上实现,但是(加密的)配置文件是分布式的P2P。
不过,在这一点上,你有相当大的服务器组件可以用在你的网站的关键路径上,所以你主要是使用P2P网络作为一种不是非常快的CDN(例如,见PeerCDN)。这就首先放弃了让你的系统去中心化的大部分好处:你仍然有在某处托管你服务器的问题,这可能意味着一些云服务,在这一点上,为什么不为你的静态内容直接使用CDN?同样,如果你担心审查制度,那么你需要担心你的服务器被审查,这使得你的网站无法使用,即使P2P部分仍然有效。
结束语
我们很容易看到一个更加去中心化网络的吸引力: 谁愿意让一群不露面的大公司来决定你能说什么或不能说什么? 当然,也有很多司法机构审查人们对网络和信息的访问。我们很容易看到P2P内容分发系统的成功(尽管在很大程度上是为了分发其他人拥有版权的内容)并得出结论说这是解决网络中心化问题的办法。
不幸的是,由于上述原因,我认为这不是真正正确的结论。虽然网络从表面上看有点像一个内容分发系统,但它实际上是一个完全不同的东西,它有更广泛的使用案例和更严格的安全和性能要求。在P2P基础上重建一些较简单的系统是可能的,但网络作为一个整体是一个不同的故事,即使是看起来简单的系统,其内部也往往相当复杂。当然,网络已经有近30年的时间发展成现在的样子,可能有一些技术改进可以让我们建立一个具有类似属性的去中心化系统,但我不认为这是我们今天真正理解的事情。
Though see X in which these roles are sort of reversed. ↩︎
Interestingly, within certain limits latency doesn’t have that much impact on how fast you can send the data because the rate control algorithms can adjust for latency. ↩︎
Allan Schiffman used to call this a “distributed single point of failure”. ↩︎
Or, as the nerds say, “unity”. ↩︎
Bitcoin Sees Influx Of New Capital: First-Time Buyers Add 140,000 BTC
On-chain data shows the supply held by new Bitcoin buyers has seen a jump recently, a sign that the ...

Neurolov and Deepbook AI Build DeFi Browser Backed by Distributed GPUs
According to Neurolov, this latest partnership with Deepbook AI allows users to enjoy smooth DeFi ex...

BTC Price Action: Michaël van de Poppe Eyes $110K Entry Zone
The crypto analyst, Michaël van de Poppe, published an essential update regarding altcoins. As $BTC ...