Sin7y技术解读:交易并行执行



前言
本次调研对比了类似以太坊的实现系统,分析了交易并行执行的难点和可能性。链本身基于 Account 模型设计,而不是采用 UTXO 模型。
调研对象
1.国内的众多 联盟链 ,如 FISCO-BCOS,支持并行执行 block 内部的交易验证。
2.Khipu, 公链 项目,以太坊协议的 scala 实现。
3. Aptos ,公链项目,Move 虚拟机。
交易并行执行的难点
我们先来回顾一下传统的交易执行过程:
执行模块从区块中取出一个个交易,然后依次去执行。执行的过程中会修改最新的世界状态,一笔交易执行完成后进行状态累加,到达区块完成后的最新的世界状态。下一区块的的执行时又严格依赖上一个区块执行后的世界状态,所以传统的交易线性执行过程无法很好的进行并行执行优化。

目前在以太坊的并行方案中,主要存在以下几点冲突:
1.账户冲突。如果两个线程同时对一个地址账号的余额或者其他属性进行处理,能否跟顺序处理的结果保持一致,也就是世界状态是否是一个确定的有限状态机。
2.同一个地址 Storage 存储冲突。两个合约变量都对同一个全局变量进行了存储修改。
3.跨合约调用冲突。本来合约 Ar 先部署,合约 B 需要等到合约 A 部署完成之后,去调用合约 A ,但是当交易并行之后,并没有这种先后顺序,这就存在着冲突。
交易并行方案对比
FISCO-BCOS
概述
FISCO-BCOS 2.0 在处理交易的过程中运用了图结构,设计了一种基于 DAG 模型的并行交易执行器(PTE, Parallel Transaction Executor)。PTE 能充分发挥多核处理器优势,使区块中的交易能够尽可能并行执行。同时对用户提供简单友好的编程接口,使用户不必关心繁琐的并行实现细节。基准测试程序的实验结果表明,相较于传统的串行交易执行方案,理想状况下 4 核处理器上运行的 PTE 能够实现约 200% ~ 300% 的性能提升,且计算方面的提升跟核数成正比,核数越多性能越高。
方案细节
一个无环的有向图被称为有向无环图(DAG)。在一批交易中,可以通过一定的方式识别出各个交易占用的互斥资源,再根据交易在 Block 中的顺序以及互斥资源的占用关系构造出一个交易依赖的 DAG 图。如下图所示,凡是入度为 0 (无被依赖的前序任务)的交易均可以并行执行。基于左图的原始交易列表的顺序进行拓扑排序后,可以得到右图的交易 DAG。

模块架构

• 用户直接或间接通过 SDK 发起交易。
• 随后交易在节点间同步,拥有打包权的节点调用打包器(Sealer)从(TxPool)中取出一定量交易并将其打包成一个区块。此后,区块被发送至共识单元(Consensus)准备进行节点间共识。
• 达成共识前需要执行交易验证,此处便是 PTE 工作的开始。从架构图中可以看到,PTE 首先按序读取区块中的交易,并输入到 DAG 构造器(DAG Constructor)中。DAG 构造器会根据每笔交易的依赖项,构造出一个包含所有交易的交易 DAG,PTE 随后唤醒工作线程池,使用多个线程并行执行交易 DAG。汇合器(Joiner)负责挂起主线程,直到工作线程池中所有线程将 DAG 执行完毕。此时 Joiner 负责根据各个交易对状态的修改记录计算 state root 及 receipt root,并将执行结果返回至上层调用者。
• 区块验证通过后,区块上链。在交易执行完成后,若各个节点状态一致,则达成共识。区块随即写入底层存储(Storage),被永久记录于区块链上。
交易 DAG 构造流程

1.从打包好的区块中取出区块的所有交易。
2.将交易数量作为最大顶点数量初始化一个 DAG 实例。
3.按序读出所有交易。如果一笔交易是可并行交易,则解析其冲突域,并检查是否有之前的交易与该交易冲突。若存在冲突,则在相应交易间构造依赖边。若该交易不可并行,则认为其必须在前序的所有交易都执行完后才能执行,因此在该交易与其所有前序交易间建立一条依赖边。
备注:都建立依赖边之后则无法并行,只能顺序执行。

1.主线程会首先根据硬件核数初始化一个相应大小的线程组,若获取硬件核数失败,则不创建其他线程.
2.当 DAG 尚未执行完毕时,线程循环等待从 DAG 的 waitPop 方法以取出入度为 0 的就绪交易。若成功取出待执行的交易,则执行该交易,执行后将后续的依赖任务的入度减 1 。若有交易入度被减至 0 ,则将该交易加入 topLevel 中。若失败,则表示 DAG 已经执行完毕,线程退出。
问题与解决方法
1.对于同一个区块,如何确保所有的节点执行完成,状态一致(三个 root 匹配)?
FISCO BCOS 采用验证 state root、transaction root 和 receipt root 三元组是否相等的方式来判断状态是否达成一致。transaction root 是根据区块内的所有交易计算出的一个哈希值,只要所有共识节点处理的区块数据相同,transaction root 必定相同。由于这一点比较容易保证,因此重点在于如何保证交易执行后生成的 state 和 receipt root 相同。
众所周知,对于在不同 CPU 核心上并行执行的指令,指令间的执行顺序无法提前预测。并行执行的交易也存在同样的情况。在传统的交易执行方案中,每执行一笔交易,state root 便发生一次变迁,同时将变迁后的 state root 写入交易回执中。所有交易执行完后,最终的 state root 就代表了当前区块链的状态,同时再根据所有交易回执计算出一个 receipt root。
可以看出,在传统的执行方案中,state root 扮演着一个类似全局共享变量的角色。当交易被并行且乱序执行后,传统计算 state root 的方式显然不再适用。这是因为在不同的机器上,交易的执行顺序一般不同,此时无法保证最后的 state root 的一致性。同理,receipt root 的一致性也无法得到保证。
在 FISCO BCOS 中,先并行执行交易,将每笔交易对状态的改变历史记录下来,待所有交易执行完后,再根据这些历史记录综合计算出一个 state root。由此就可以保证即使并行执行交易,最后共识节点仍然能够达成一致。
2. 如何判定两笔交易是否有依赖?
若两笔交易本来无依赖关系但被判定为有,则会导致不必要的性能损失;反之,如果这两笔交易会改写同一个账户的状态却被并行执行了,则该账户最后的状态可能是不确定的。因此, 依赖关系的判定是影响性能甚至能决定区块链能否正常工作的重要问题。
在简单的转账交易中,我们可以根据转账的发送者和接受者的地址来判断两笔交易是否有依赖关系。
以如下 3 笔转账交易为例:A→B,C→D,D→E。可以很容易看出,交易 D→E 依赖于交易 C→D 的结果,但是交易 A→B 和其他两笔交易没有联系,因此可以并行执行。
这种分析在只支持简单转账的区块链中是正确的。但因为我们无法准确知道用户编写的转账合约中到底有什么操作,这种分析一旦放到图灵完备、运行 智能合约 的区块链中,则不够准确。
可能出现的情况是:A→B 的交易看似与 C、D 的账户状态无关,但是在用户的底层实现中,A 是特殊账户,通过 A 账户每转出每一笔钱必须要先从 C 账户中扣除一定手续费。在这种场景下, 3 笔交易均有关联,则它们之间无法使用并行的方式执行。若还按照先前的依赖分析方法对交易进行划分,则必定会出现问题。
那么我们能否做到根据用户的合约内容自动推导出交易中实际存在哪些依赖项?答案是否定的。正如静态分析中提到的,我们很难分析出合约依赖项以及执行过程。
FISCO BCOS 将交易依赖关系的指定工作交给更熟悉合约内容的 开发者 。具体来讲,交易依赖的互斥资源可以由一组字符串表示。FISCO BCOS 暴露接口给到开发者,开发者以字符串形式定义交易依赖的资源,告知链上执行器,执行器则根据开发者指定的交易依赖项自动将区块中的所有交易排列为交易 DAG。比如在简单转账合约中,开发者仅需指定每笔转账交易的依赖项是{发送者地址+接收者地址}。进一步讲,假如开发者在转账逻辑中引入了另一个第三方地址,那么依赖项就需要定义为{发送者地址+接受者地址+第三方地址}。
这种方式实现起来较为直观简单,也比较通用,适用于所有智能合约,但也相应增加了开发者肩上的责任。开发者在指定交易依赖项时必须十分小心,如果依赖项没有写正确,后果将无法预料。
并行框架合约
FISCO BCOS 为了开发者能够使用并行合约这一套框架设定了一些合约编写的规范, 细节如下:
并行互斥
两笔交易是否能被并行执行,依赖于这两笔交易是否存在 互斥 。互斥是指两笔交易各自 操作合约存储变量的集合存在交集 。
例如,在转账场景中,交易是用户间的转账操作。用 transfer(X, Y) 表示从 X 用户转到 Y 用户的转账接口,则互斥情况如下:

• 互斥参数 :合约 接口 中,与合约存储变量的“读/写”操作相关的参数。例如转账接口为 transfer(X, Y),X 和 Y 都是互斥参数。
• 互斥对象 :一笔交易中,根据互斥参数提取出来的、具体的互斥内容。例如转账接口为 transfer(X, Y),一笔调用此接口的交易中,具体的参数是 transfer(A, B),则这笔操作的互斥对象是[A, B];另外一笔交易调用的参数是 transfer(A, C),则这笔操作的互斥对象是[A, C]。
判断同一时刻两笔交易是否能并行执行,就是判断两笔交易的互斥对象是否有交集。相互之间交集为空的交易可并行执行。
FISCO-BCOS 提供了两种编写并行合约的方式,一种是 solidity 合约,另一种是预编译合约。这里只介绍 solidity 合约,预编译合约同理。
solidity 合约并行框架
编写并行的 solidity 合约时,在基础上只需要将 ParallelContract.sol 作为需要并行的合约的基类,并调用 registerParallelFunction()方法,注册可以并行的接口即可。
parallelContract 代码如下:

以下是基于并行框架合约进行编写的转账合约:

确定接口是否可并行
可并行的合约接口,必须满足:
• 无调用外部合约。
• 无调用其它函数接口。
确定互斥参数
在编写接口前,需要先确定接口的互斥参数,接口的互斥即是对全局变量的互斥。互斥参数的确定规则为:
• 接口访问了全局 mapping,mapping 的 key 是互斥参数。
• 接口访问了全局数组,数组的下标是互斥参数。
• 接口访问了简单类型的全局变量,所有简单类型的全局变量共用一个互斥参数,用不同的变量名作为互斥对象。
例如:合约里有多个简单类型的全局变量,不同接口访问了不同的全局变量。如需将不同接口并行,则需要在修改了全局变量的接口参数中定义一个互斥参数,调用时指明使用了哪个全局变量。在调用时,主动给互斥参数传递相应修改的全局变量的“变量名”,用以标明此笔交易的互斥对象。如:setA(int x)函数中修改了全局参数 globalA,则需要将 setA 函数定义为 set(string aflag, int x), 在调用时,传入 setA("globalA", 10),用变量名“globalA”来指明此交易的互斥对象是 globalA。
确定互斥参数后,根据规则确定参数类型和顺序,规则为: 确定参数类型和顺序
- 接口参数仅限: string、address、uint 256、int 256 (未来会支持更多类型)。
- 互斥参数必须全部出现在接口参数中。
- 所有互斥参数排列在接口参数的最前。
可以看出, FISCO-BCOS 交易并行其实很大程度依赖用户编写合约的规范。如果用户编写合约不规范,系统贸然的进行了并行执行,则有可能会造成账本 root 不一致的问题 。
Khipu
概述
与 FISCO-BCOS 的观点不同,Khipu 认为让用户在编写合约的时候识别和标明会发生静态冲突的地址范围并且不出错是不现实的。
竞态是否会出现、在何处出现、在什么条件下会出现,只有当确定性获取涉及到当前状态后才可以做判断。以目前的合约编程语言而言,几乎不可能通过对代码进行静态分析来获取完全无误并且没有遗漏的结果。
Khipu 针对这方面做了比较全面的尝试,并且完成了工程实现。
方案细节
在 Khipu 的实现方案中,同一个区块里面的每条交易都从前一个区块的世界状态开始,然后并行执行,在执行过程中记录下所有的理想经历路径上遇到的以上三种竞态。在并行执行阶段结束后,转入合并阶段。合并阶段开始逐条合并并行的世界状态,每合并一条交易时,先从记录下来的静态条件中判断是否已经与前面已经合并的竞态条件有冲突。如果没有,直接合并。如果有,则将这条交易以之前已经合并的世界状态为起点再执行一次。最后合并的世界状态将用区块的哈希做最后的校验。这是最后的一道防线,如果校验有误,则放弃前面的并行方案,将区块内的交易重新串行执行。
并行度指标
Khipu 在这里引入了一个并行度指标,即一个区块内能够不需要再次执行就可以直接合并结果的交易比例。Khipu 通过对以太坊从创世区块到最新的区块进行几天的重放观测发现,这个比例(并行度)平均可以达到 80% 。
总体而言,如果计算任务可以被完全并行化,单链的可扩展性就会是无限的,因为总是可以往一个节点里添加更多的 CPU 核心数量。若事实并非如此,则最大的理论速率就受限于 安达尔定理 :
你能给系统进行提速的极限取决于那些不能进行并行化的部分的倒数。也就是说,如果你可以进行 99% 的并行化,那么你就可以提速到 100 倍。但如果你只能实现 95% 的并行化,那么你就只能提速到 20 倍。
冲突标记
在以太坊所有的交易重放下来看,大概有 80% 的交易是可以并行化的,有 20% 不能并行化,所以 Khipu 对以太坊提速的平均效率是 5 倍左右。
通过对 evm 代码指令的解读可以发现,冲突的地方是一些有限的指令对于 stroage 产生了读写过程,因此可以通过记录这些读写的地方形成一个读写集合。仅仅利用静态的代码分析无法确保这些过程都被记录,所以需要在处理每个区块里面的交易时对每一笔交易并行的预执行一次。通过预执行过程,可以得知这些交易是否是对同一个 account 或者 storage 进行读写,然后对每笔交易产生一个 readSet 和 writeSet。简言之,预执行的过程就是首先将世界状态拷贝多份作为所有交易的初始状态。假设区块链里面存在 100 个交易,那么这 100 多交易就可以通过线程池并行执行。每个合约都有同样的初始世界状态,执行过程中会也会产生 100 个 readSet 和 writeSet ,同时也会各自产生 100 个新的状态。
预执行结束后,开始下一个阶段的处理。理想状态下,如果这 100 个 readSet 和 writeSet 没有冲突,那么就可以直接进行合并,产生这个区块里面所有交易执行完毕的最终世界状态。但是交易往往不会如此理想化,所以正确的处理方式为:先取第一个交易执行后的状态里面的 readSet、writeSet,和第二个合约执行后的 readSet、writeSet 进行对比,看他们是否有对同一个账户或者 storage 进行读写。如果有,那就意味这两笔交易存在冲突,则以第一个交易执行完成的状态作为第二个交易的起始状态,将交易二重新执行一遍。以此类推,随着不断进行合并状态机,冲突集也会不断地累加。只要后面的交易与前面的交易存在冲突就顺序执行,直到执行完所有的交易。
通过对以太坊主网的交易重放可以发现,凡是冲突多的地方,大部分是 交易所 在同一个区块进行的有互相关联的交易,这也是与该过程相符合的。

处理流程图

具体并行执行过程

Aptos
概述
Aptos 在 Diem 的 Move 语言和 MoveVM 的基础上创建了一个高吞吐量的链,实现了并行执行。Aptos 的方法是检测关联关系,同时对用户/开发者透明。也就是说,不要求交易明确声明它们使用哪一部分状态(内存位置)。
方案细节
Aptos 使用名为 Block-STM 的软件交易内存 (Software transaction Memory ) 的修改版本,基于 Block-STM 论文实现了并行执行引擎。
Block-STM 使用 MVCC(多版本并发控制)来避免写-写冲突。所有到相同位置的写入都与它们的版本一起存储,这些版本包含它们的 tx-id 和写入 tx 被重新执行的次数。当交易 tx 读取某一个内存位置的值时,它从 MVCC 中获得在 tx 之前出现的写入该位置的值,以及关联的版本, 从而判断是否有读写冲突。在 Block-STM 中,交易在区块内是预先排序的,并在执行期间在处理器线程之间划分以并行执行。在并行执行中,假设没有依赖关系执行交易,被交易修改的内存位置被记录下来。执行后,验证所有交易结果。在验证期间,如果发现一个交易访问了由先前交易修改的内存位置,则该交易无效。刷新交易的结果,重新执行交易。重复该过程,直到区块中的所有交易都被执行。当使用多个处理器内核时,Block-STM 会加快执行速度。加速取决于交易之间的相互依赖程度。
可以看到,Aptos 采用的方案和前文提到的 Khipu 大致类似,但是实现细节略有不同。主要区别如下:
• Khipu 对区块内交易采用并行执行,顺序验证的方式,而 Aptos 对区块内的交易采用并行执行,并行验证的方式。这两种方案各有优缺点。Khipu 的方案易实现,效率略低。Aptos 的 Block-STM 实现采用了诸多线程中的同步与信号操作,难以进行代码实现,但效率较高。
• 由于 Move 原生支持全局资源寻址,所以在利于并行执行的情况下,Aptos 会对交易进行重新排序,甚至是跨区块进行排序。官方宣称这个方案既可以提高并行的效率,也可以解决 MEV 问题,但是这样是否会影响用户体验则有待考虑。
• Aptos 在执行过程中会将执行得到的写集存储在内存中以获得最大的执行速度,并将其用作要执行的下一个块的缓存,任何重复的写入操作都只需要写入稳定的存储器一次。
基准测试
Aptos 针对 Block-STM 进行集成后做了相应的 benchmark, 将 10 k 交易一个区块在顺序执行情况下与并行执行情况下的表现进行了对比,结果如下:

从上图可以看到,Block STM 在 32 个线程并行执行的情况下比使用程的顺序执行实现了 16 倍的加速,而在高争用情况下,Block-STM 实现了超过 8 倍的加速。
总结
综上所述,一些方案需要用户在编写合约时按照既定的规则写存储,这样才能够被静态和动态分析发现依赖关系。 Solana 和 Sui 采用了类似的方案,只是用户感知度不同。这类方案本质上都是对于存储模型的更改以获得更好地分析结果。
Khipu 和 Aptos 的方案属于用户无感知的。即用户无需谨慎编写合约,虚拟机会在执行前进行动态分析依赖关系,从而将没有依赖关系的并行执行。这类方案实现难度较大,而且并行度在一定程度上取决于交易的账户分部情况。当交易冲突较多的时候,不断地重新执行反而会导致性能严重下降。Aptos 在论文中提到后续可能也会对用户编写合约进行一些优化,从而更好地分析依赖关系,达到更快的执行速度。
单纯的修改交易串行到并行模式在公链环境下可以带来 3 ~ 16 倍的吞吐量提升。如果能够结合大区块和大的 gas Limit 等优化,L2吞吐量可以提升百倍左右。
考虑到工程实现和效率问题,OlaVM 大概率会采用 Khipu+定制化存储模型方案。在获得性能提升的同时,避免引入 Block-STM 带来的复杂性,也便于后期更好的进行工程优化。
参考:
1.Block-STM 论文:[ 2203.06871 ] Block-STM: Scaling Blockchain Execution by Turning Ordering Curse to a Performance Blessing (arxiv.org)
2.FISCO-BCOS Github, FISCO-BCOS
3.Khipu Github, GitHub - khipu-io/khipu: An enterprise blockchain platform based on Ethereum
4.Aptos Github, GitHub - aptos-labs/aptos-core: Aptos is a layer 1 blockchain built to support the widespread use of of blockchain through better technology and user experience.
关于我们
Sin7y 成立于 2021 年,由顶尖的区块链开发者组成。我们既是项目孵化器也是区块链 技术 研究团队,探索 EVM、Layer 2、 跨链 、 隐私计算 、自主支付解决方案等最重要和最前沿的技术。团队于 2022 年 7 月推出 OlaVM 白皮书,致力于打造首个快速、可扩展且兼容 EVM 的 ZKVM。
微信公众号:Sin 7 y
官网:https://sin 7 y.org/
白皮书:https://olavm.org/
社群:http://t.me/sin 7 y_labs
官推:@Sin 7 y_Labs
邮箱:contact@sin 7 y.org
Github:Sin 7 y
研究文章(EN):https://hackmd.io/@sin 7 y

Pi Network Price Prediction, if Listed on Binance and Coinbase
The post Pi Network Price Prediction, if Listed on Binance and Coinbase appeared first on Coinpedia ...

Nexo Partners with DP World Tour to Fuse Digital Wealth with Elite Golf
As per Nexo, this latest mutual effort is a strategic engagement in which it will activate advanced ...
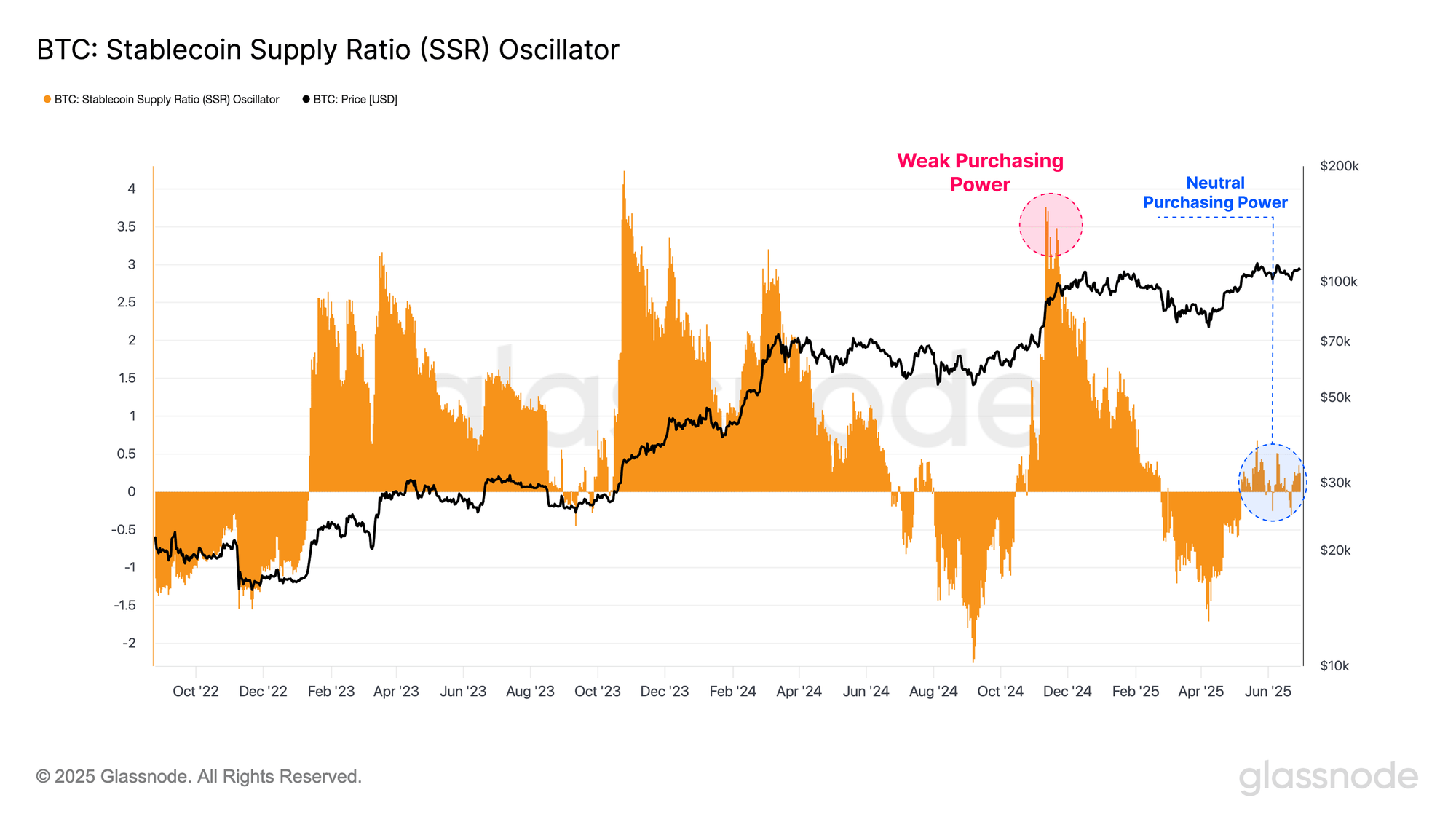
Bitcoin Latest Rally Backed By Stronger Purchasing Power: Report
Data of the Bitcoin Stablecoin Supply Ratio suggests investors have stronger purchasing power today ...