


作者:喻琰,澎湃新闻记者
·有负责大模型领域挖掘高端科技人才的猎头告诉澎湃科技,DeepSeek的用人逻辑和大模型领域其他公司的用人逻辑并无太大差异,对人才的核心标签都是“年轻高潜”,即年龄在1998年出生左右,工作经验最好不要超过五年,“聪明、理工科、年轻、经验少。”
·在业内人士看来,和国内其他大模型创业公司相比DeepSeek是幸运的,没有融资压力,不需要向投资人证明,不需要兼顾模型的技术迭代和产品应用的优化。但作为一家商业公司,巨资投入后,或早或晚都要面临目前其他模型公司面临的压力和挑战。
2024年中国大模型圈最火的是哪家?杭州深度求索人工智能基础技术研究有限公司(以下简称DeepSeek)一定是有力竞争者,如果说作为去年年中大模型价格战的发起者,DeepSeek初入公众视野,到了岁末年初先后对外发布开源模型DeepSeek-V3和推理模型DeepSeek-R1后,DeepSeek彻底引爆了大模型圈的舆论场。人们一边惊讶于其高性价比的训练成本(据说DeepSeek-V3仅花费了557.6万美元的训练成本),另一方面为其模型开源和公开技术报告的行为鼓掌称赞。DeepSeek-R1的发布,让不少科学家、开发者和用户们都兴奋不已,甚至认为DeepSeek是OpenAI的o1等推理模型强有力的竞争对手。
这家低调的公司为何可以做到用极低的训练成本做出性能不差的大模型?它今天的火爆得益于它做对了什么?在未来的日子里,它要想继续在“模圈”乘风破浪一路向前将会面临怎样的挑战?
算法创新使得算力成本大幅下降
“DeepSeek投入早,积累多,在算法上有自己的特色。”国内一家明星大模型创业公司的高管在提及DeepSeek时表示,他认为DeepSeek之所以能火出圈,最核心的优势还是得益于算法上的创新,“中国公司因为缺乏算力,所以在算力成本上会比OpenAI更注重节约。”
根据DeepSeek公布的DeepSeek-R1信息显示,其在后训练阶段(Post-Training)大规模使用了强化学习(Reinforcement learning)技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
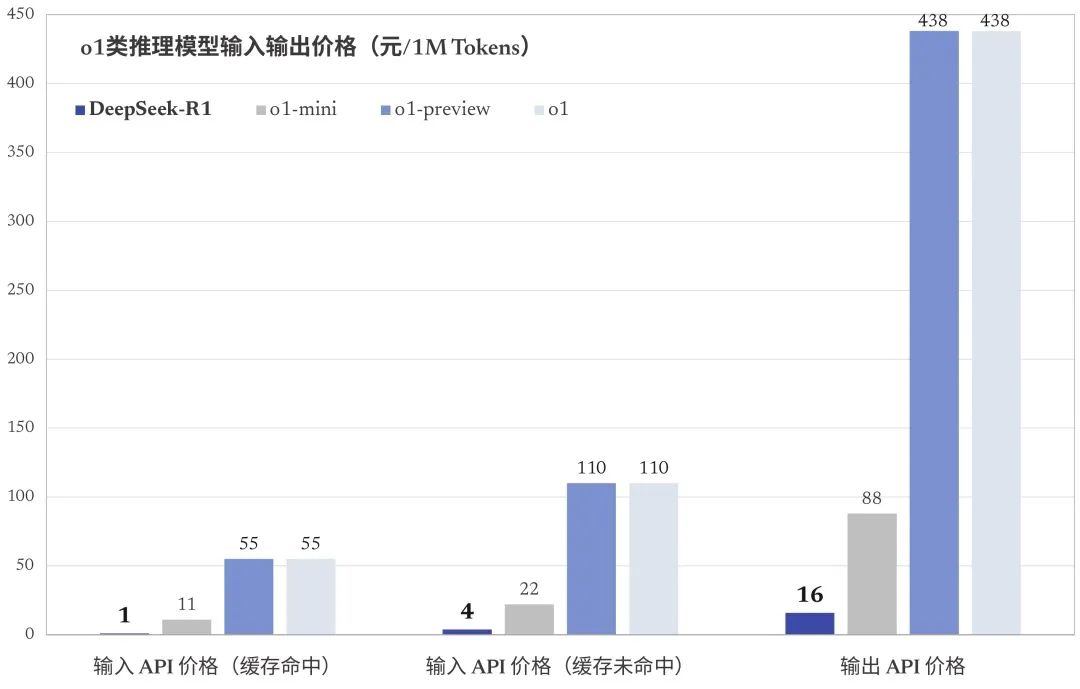
DeepSeek-R1 API价格
DeepSeek创始人梁文锋此前曾多次强调,DeepSeek致力于开辟差异化技术路线,而非复制OpenAI的模式,DeepSeek必须想出更有效的方法来训练其模型。
“他们使用了一系列工程技巧优化了模型架构,比如创新地使用模型混合方法等,本质的目的是透过工程化降低成本使其可以盈利。”在科技行业从业多年的资深人士告诉澎湃科技。
根据DeepSeek对外披露的信息可以发现,其在MLA(Multi-head Latent Attention)多头潜在注意力机制和自研的DeepSeekMOE(Mixture-of-Experts混合专家模型)结构方面取得了重大进展,这两种技术设计通过减少训练计算资源,使DeepSeek模型更具成本效益,也提升了训练效率。根据研究机构Epoch AI的数据,DeepSeek 的最新模型非常高效。
在数据方面,与OpenAI“海量数据投喂”的方式不同,DeepSeek利用算法把数据进行总结和分类,经过选择性处理之后,输送给大模型,提高了训练效率,也降低了DeepSeek的成本。DeepSeek-V3的出现,实现了高性能与低成本的平衡,给大模型发展提供了新的可能性。
“未来或许不需要超大规模的GPU集群了。”在DeepSeek的高性价比模型发布后,OpenAI创始成员Andrej Karpathy表示。
清华大学计算机系长聘副教授刘知远向澎湃科技表示,DeepSeek的出圈,恰恰证明了我们的竞争优势所在,通过有限资源的极致高效利用,实现以少胜多。R1的发布,正表明我们与美国的AI实力差距明显缩小了。《经济学人》也在最新一期报道中称:“DeepSeek以其低成本的训练与模型设计的创新同步改变科技行业。”
现任Google DeepMind的首席执行官兼联合创始人德米斯·哈萨比斯(Demis Hassabis)表示,虽然尚不完全清楚DeepSeek在训练数据和开源模型方面对西方系统的具体依赖程度,但必须承认该团队所取得的成就确实令人印象深刻。一方面,他认可中国拥有非常强大的工程能力和规模化能力,另一方面,他也指出,西方仍然领先,并且需要考虑如何保持西方前沿模型的领先地位。
多年聚焦的厚积薄发
DeepSeek之所以能取得这些创新并非一日之功,而是“孵化”数年之久,长期谋划后的结果。梁文锋也是头部量化私募幻方量化的创始人。Deepseek被认为充分利用了幻方量化积累的资金、数据和卡。
梁文锋本科、研究生毕业于浙江大学,拥有信息与电子工程学系本科和硕士学位。2008年起,他开始带领团队使用机器学习等技术探索全自动量化交易。2015年,幻方量化成立,次年推出第一个AI模型,第一份由深度学习生成的交易仓位上线执行,2018年确立以AI为主要发展方向。2020年,幻方累计投资超亿元、占地面积相当于一个篮球场的AI超级计算机“萤火一号”正式投入运作,号称可以匹敌4万台个人电脑的超级算力。2021年,幻方投入十亿建设“萤火二号”,“配备了1万张A100GPU芯片”。当时国内超过1万枚GPU的企业不超过5家,而且除了幻方量化之外,其他4家公司都是互联网大厂。
2023年7月,DeepSeek正式成立,进军通用人工智能领域,至今从未对外融资。
“有相对充裕的卡,没有融资压力,前面几年只做模型不做产品,让DeepSeek和其他国内大模型公司相比显得更加单纯、聚焦,能够在工程技术和算法上有所突破。”上述国内大模型公司高管表示。
此外,在大模型行业日渐走向封闭,OpenAI被戏称为CloseAI时,DeepSeek的模型开源和公开技术报告的行为也赢得了开发者们的众多好评,使得其技术品牌迅速在海内外大模型市场得以脱颖而出。
有科研人员告诉澎湃科技,DeepSeek的开放性非常了不起,模型V3和R1的开源抬高了市场上开源模型的基准水平。
成功证明了年轻人的力量
“DeekSeek取得的成功也让大家看到了年轻人的力量,从本质上来说这一代人工智能发展更需要年轻的头脑。”一位模型公司的人士向澎湃科技说。
此前,OpenAI前政策主管、Anthropic联合创始人Jack Clark认为DeepSeek雇用了“一批高深莫测的奇才”,对此,梁文峰在接受自媒体采访时曾表示,并没有什么高深莫测的奇才,都是来自国内顶尖高校的毕业生、没毕业的博四、博五实习生,还有一些毕业才几年的年轻人。
从目前已有的媒体公开报道中可以看出,DeepSeek团队最大的特点是名校、年轻,即使是团队Leader级别,年纪也多在35岁以下。不到140人的团队,工程师和研发人员几乎都来自清华大学、北京大学、中山大学、北京邮电大学等国内顶尖高校,工作时间都不长。
有负责大模型领域挖掘高端科技人才的猎头告诉澎湃科技,DeepSeek的用人逻辑和大模型领域其他公司的用人逻辑并无太大差异,对人才的核心标签都是“年轻高潜”,即年龄在1998年出生左右,工作经验最好不要超过五年,“聪明、理工科、年轻、经验少。”
不过,前述猎头也表示,大模型创业公司本质还是一家创业公司,并非不想招到海外顶尖AI人才,而现实环境是,海外顶尖AI人才愿意回来的不多。
一位不愿透露姓名的DeepSeek员工向澎湃科技透露,公司管理很扁平化,自由交流的氛围比较好。梁文峰平日行踪不定,大多数时间大家和他都是线上交流。
该员工此前曾在国内大厂做大模型技术研发,但感觉自己在大厂更像一颗螺丝钉,无法创造价值,最终选择加入DeepSeek。在他看来,DeepSeek目前更专注底层模型技术。
DeepSeek的工作氛围完全自下而上,自然分工,每个人对于卡和人的调动都不设上限,“自带想法,不需要Push。在探索过程中,他遇到问题,自己就会拉人讨论。”梁文峰此前在接受采访时称。
“认为中国AI已经超越美国还为时过早”
美国商业媒体Business Insider分析认为,新发布的R1表明,中国可以与业内一些顶尖的人工智能模型相媲美,并与美国硅谷前沿发展保持同步;其次,开源如此先进的人工智能也可能对那些试图通过出售技术来获取巨额利润的公司构成挑战。
不过,现在就高呼“中国 AI 已经超越美国”或许还为时过早。刘知远公开表示,需要警惕舆论从极度悲观转向极度乐观,觉得我们已经全面超越、遥遥领先了,“远远没有”。刘知远认为,当前AGI新技术还在加速演进,未来发展路径还不明确,中国仍在追赶的阶段,虽然已经不是望尘莫及,但也只能说尚可望其项背,“在别人已经探索出的路上跟随快跑还是相对容易的,接下来如何在迷雾中开拓新路,才是更大的挑战。”
“现在太卷了,大家都太着急了,没有意识到DeepSeek最后跑出来了。”接近DeepSeek的人向澎湃科技感慨,行业变化的速度太快,无法预测下一步能做什么,只能看下一个Q3季度的变化。
德米斯·哈萨比斯一方面认可中国拥有非常强大的工程能力和规模化能力,另一方面,他也指出,西方仍然领先,并且需要考虑如何保持西方前沿模型的领先地位。
虽然此前梁文峰对外表示,DeepSeek只做模型不做产品。但是作为一家商业化公司,几乎不可能一直只做模型不做产品。1月15日,DeepSeek官方App正式发布。接近DeepSeek的人士向澎湃科技表示,商业化已经被DeepSeek提上日程。
在业内人士看来,和国内其他大模型创业公司相比DeepSeek是幸运的,没有融资压力,不需要向投资人证明,不需要兼顾模型的技术迭代和产品应用的优化。但作为一家商业公司,巨资投入后,或早或晚都要面临目前其他模型公司面临的压力和挑战。“这次出圈为DeepSeek在商业化前夕做了一次成功的营销,但未来真正商业化后,需要接受市场的检验,能否继续破浪前行尚难定论。”上述模型公司人士表示。
可以确定的是,DeepSeek未来将要面临更多的压力和挑战,通往通用模型的竞赛现在才刚刚拉开序幕,谁能赢下去还取决于持续投入的资金和技术的迭代。但业内人士也都认为,“对于国内模型行业来说,有像DeepSeek这样具备真正技术实力的公司加入,是件好事。”


