


DeepSeek V4 终于上线了。这是一个被等了将近五个月的时刻。1T 参数的 MoE 主模型 + 285B 参数的 Flash 版本,全套 1.6T 的 Pro 版本紧随其后,完整开源到 GitHub,Apache 2.0 协议,权重和部署代码同步释出。
模型一出来,资本市场就用三种相互独立又彼此咬合的方式,给出了它们的回答。
资本市场的不同反应
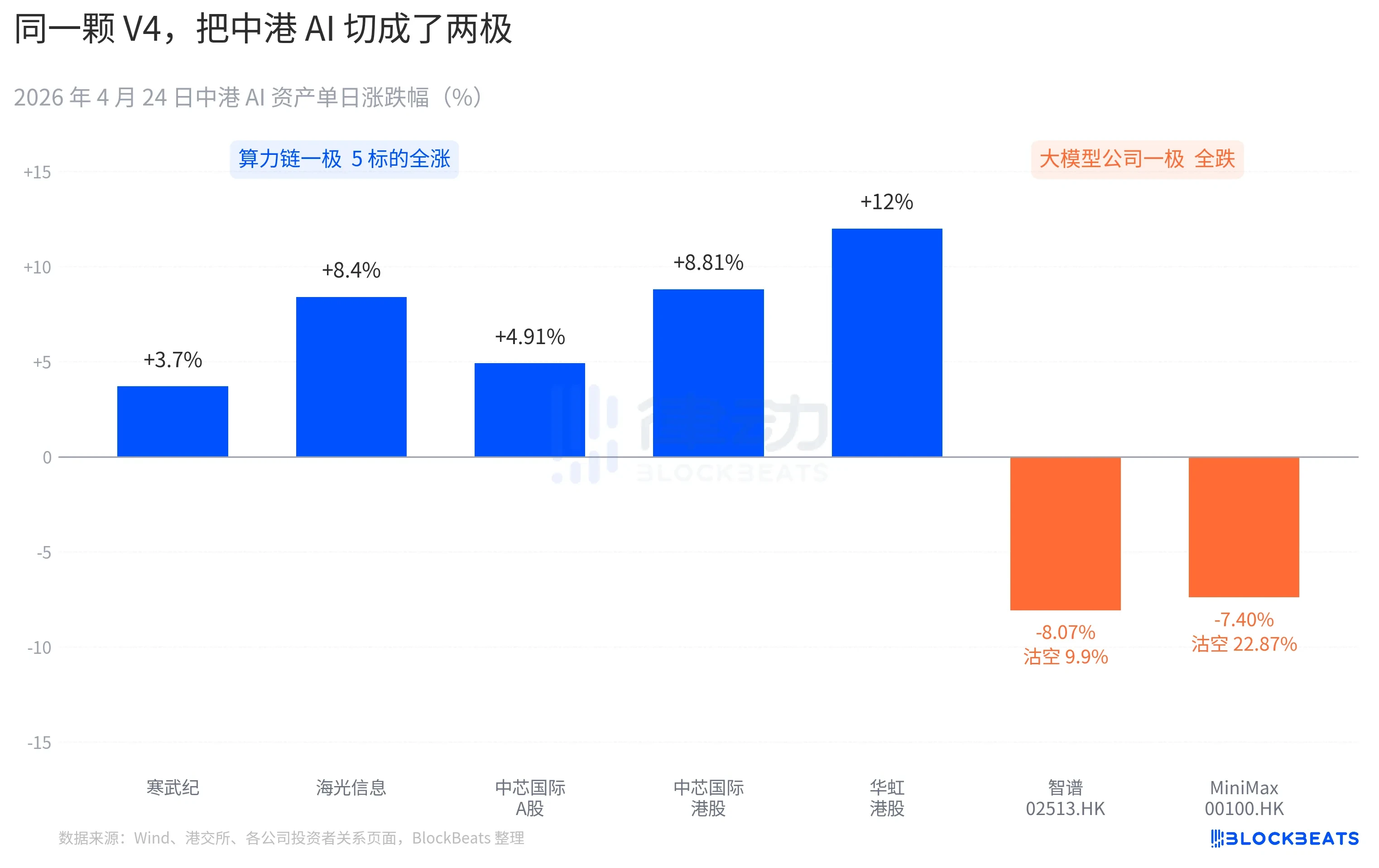
A 股算力链这一头几乎全线跳涨。寒武纪走出了 11 连阳,单日涨 3.7%,月内累计涨幅突破 60%。海光信息盘中触及 10% 涨停,收盘 +8.4%。中芯国际 A 股 +4.91%,港股 +8.81%。华虹港股最高拉到 +18%,收盘 +12%。科创芯片国泰 ETF 单日吸金 24 亿元,规模站上历史高点。
港股大模型公司这一头是另一种颜色。智谱(02513.HK)跌 8.07%,沽空比例 9.9%。MiniMax(00100.HK)跌 7.40%,沽空比例飙到 22.87%。后者是港股 AI 板块过去三个月最高的单日做空数据。这两家公司都是 2025 年下半年港股 AI 上市潮的代表,IPO 招股书里写的核心竞争力是同一句话,「自研基座大模型」。
太平洋另一头的反应同样具体。英伟达昨晚开盘下跌 1.8%,盘中一度跌至 -2.6%,全天收平。彭博的市场速评把这次盘整与 1 月 27 日的 V3「DeepSeek 时刻」做了对比。区别在于,1 月那一次是恐慌式抛售,单日蒸发 6000 亿美元市值。这一次更像一次重新计价,量级温和但方向明确。买方机构的研究纪要里出现了一句新表述,「中国 AI 推理需求开始与北美 AI 推理需求脱钩」。
把这三块盘面叠在一起,就是 V4 落地之后 24 小时之内被市场写下的第一份判决书。开源胜出之后,钱开始重新选边,能定价的不再是模型本身,是模型跑在哪块卡上、装在哪条产业链里。
30 天 11 个新模型,V4 给开源阵营添一把火
V4 发布的时间窗口本身就是这次反应被放大的一部分原因。
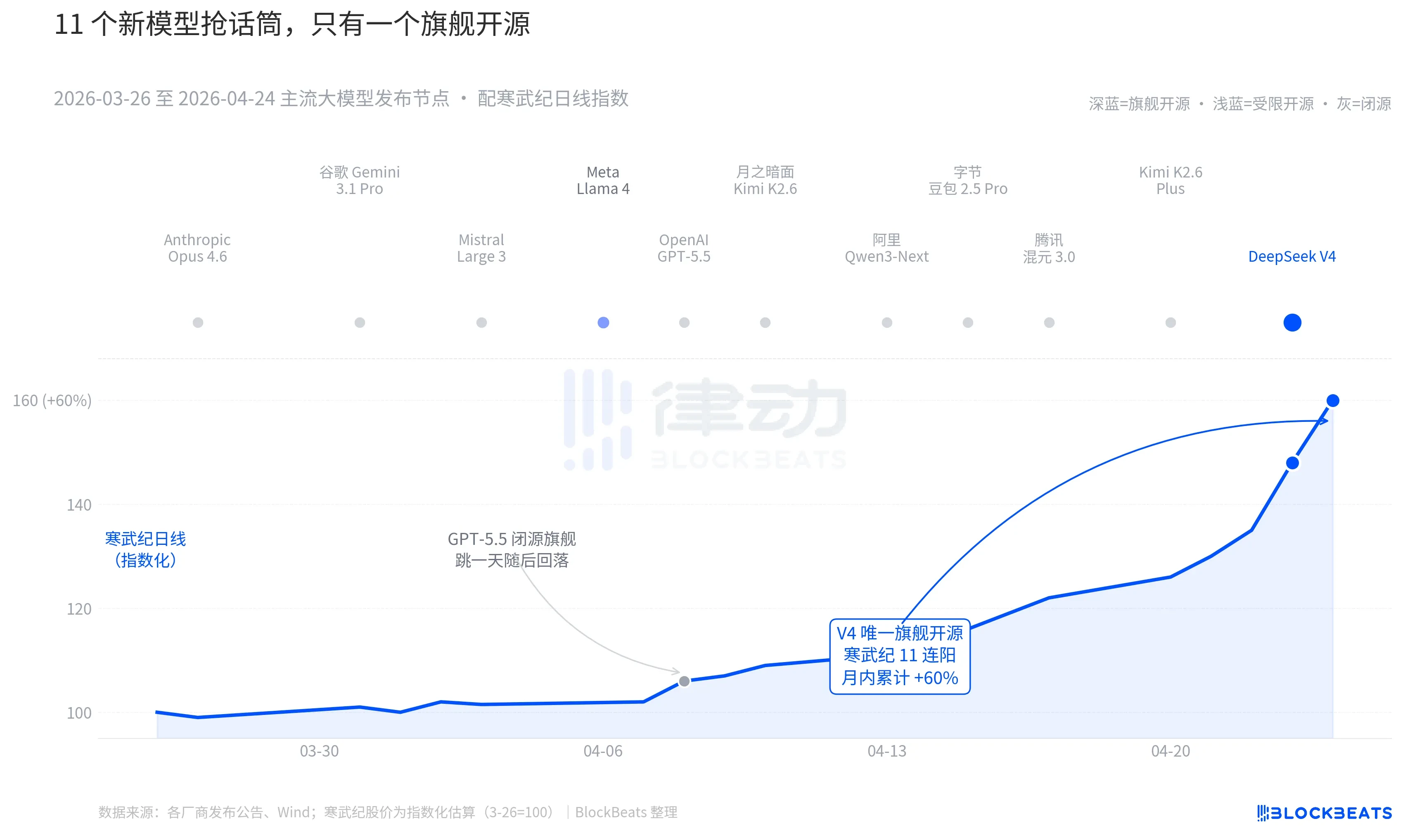
把镜头拉到过去 30 天。3 月 26 日到 4 月 24 日之间,全球至少有 11 个有显著影响力的大模型发布或重大更新,名单覆盖几乎所有主要玩家。Anthropic Opus 4.6、谷歌 Gemini 3.1 Pro、OpenAI GPT-5.5、Mistral Large 3、Meta Llama 4、月之暗面 Kimi K2.6、阿里 Qwen3-Next、字节豆包 2.5 Pro、腾讯混元 3.0、Kimi K2.6 Plus,最后是 4 月 23 日凌晨发布的 DeepSeek V4。
平均下来,每 2.7 天就有一个新模型出炉。这是连基金经理都来不及读完发布稿的速度。但翻一遍这 30 天的中港 AI 资产 K 线,能在盘面上留下持续痕迹的只有一个名字。4 月 8 日的 GPT-5.5 带动英伟达单日涨 4.2%,一日见顶。然后是 4 月 23-24 日的 DeepSeek V4,带动中港算力链走出连续跳涨。
差别不在模型能力本身。这 11 个模型在 LMArena 排行榜上的差距,多数情况下不超过 50 分,处在「同一段位」的窄带里。差别在两件事的叠加。
第一件是开源。前 10 个模型里只有 Llama 4 开源,但 Llama 4 的权重协议附了一长串商用限制条款,欧美开发者社区评价冷淡,OpenRouter 上线第三天就掉出前十。V4 的协议是 Apache 2.0,权重无门槛、商用无限制、推理代码同步释出。这是过去半年里第一个让闭源阵营在性能、价格、开放度三个维度同时承压的旗舰开源模型。
第二件是时机。在闭源阵营连续放大招的背景下,开源叙事正在被反复挤压。Opus 4.6 把代码任务的 SWE-Bench 推到新高,GPT-5.5 把每百万 token 价格定在了 1.25 美元的下沉锚点。开源能不能追上闭源,这场争论在硅谷已经持续两年。V4 用一个月活预估冲到 9000 万的开源旗舰,把这场争论按下了暂停键。
按一位国内大型基金经理在路演里的说法,「V4 之前我们对开源大模型估值留了一个折扣,V4 之后这个折扣开始反着收。」
DeepSeek 把算力供应链的定价表换了一张
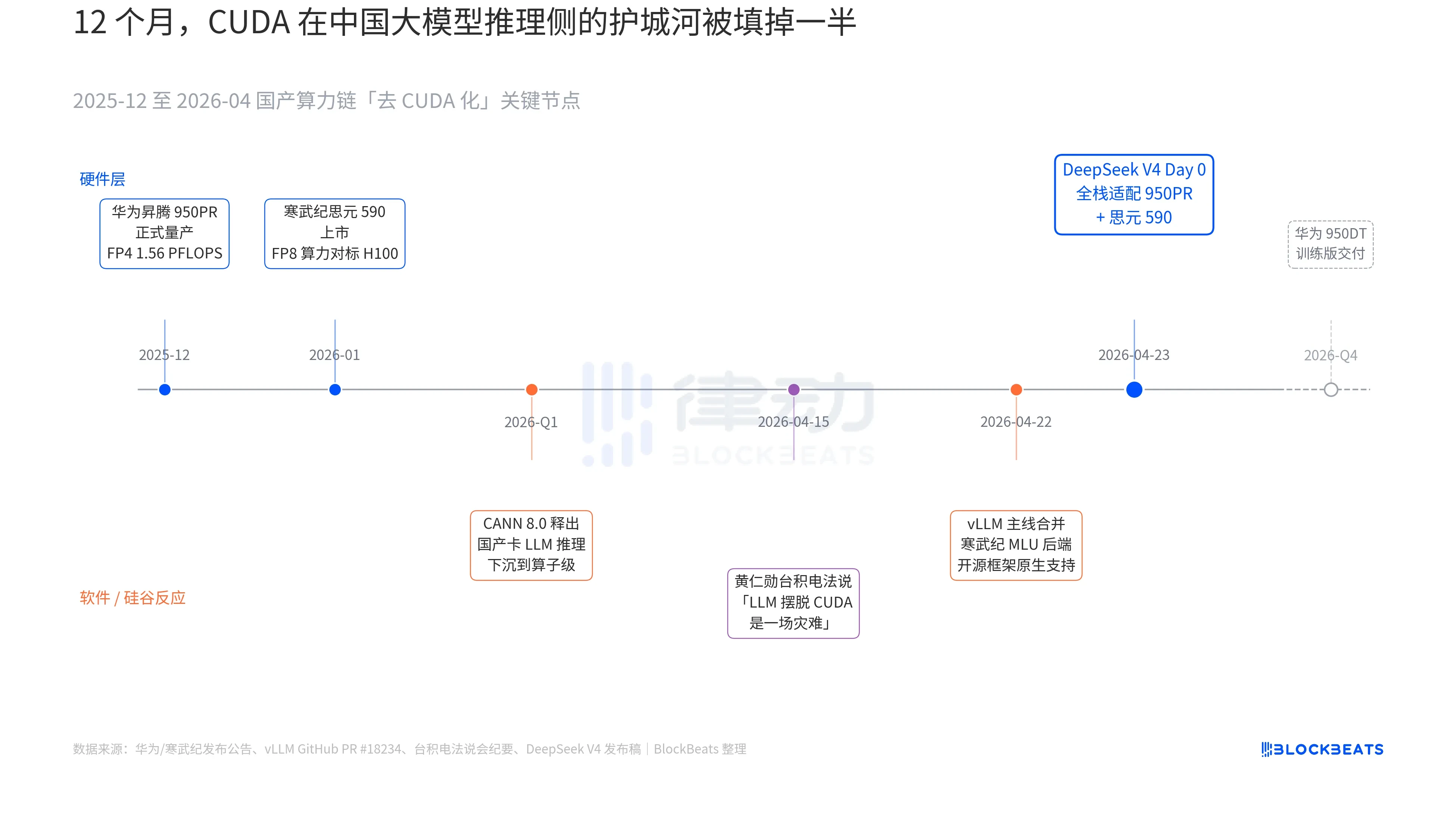
V4 发布稿里有一行字之前从未出现在任何中国大模型的官方文档里:「Day 0 全栈适配寒武纪思元 590 与华为昇腾 950PR,部署代码同步开源。」这一行字的分量,要把过去 12 个月里三条平行展开的暗线接到一起才看得明白。这三条暗线分别属于硬件、软件和硅谷的反应。
第一条暗线在芯片侧。华为昇腾 950PR 在 2025 年 12 月正式量产,FP4 算力 1.56 PFLOPS,HBM 容量 112GB,是国产 AI 芯片第一次在硬指标上对标英伟达 B 系列。在 V4 这种 1T 参数的 MoE 推理任务里,单卡吞吐较 H20 提升 2.87 倍。配套的 CANN 8.0 软件栈,把 LLM 推理框架的优化下沉到算子级别,DeepSeek 公开的 Benchmark 显示,V4 在昇腾超节点(8 卡 950PR)上的端到端推理延迟比同等规模的 H100 集群低 35%。寒武纪思元 590 的数据更激进,单芯片 FP8 算力对标 H100,售价不到一半。
第二条暗线在软件侧。vLLM 主线在 4 月 22 日合并了寒武纪 MLU 后端 PR,开源推理框架第一次原生支持非英伟达的国产 GPU。海光信息的 DCU 通过 ROCm 生态走另一条路,但能把 V4 的 MoE 路由层完整跑通。这意味着 V4 的部署不再是「只能在某家国产卡上跑」,而是「可以在多家国产卡之间选」。生态对单点供应商的依赖被打破,这是 production 的关键拐点。
第三条暗线来自硅谷。4 月 15 日,黄仁勋在台积电的法说会上被分析师追问中国国产算力的进展,原话冷峻而具体,「如果他们真的能让 LLM 摆脱 CUDA,对我们来说会是一场灾难(a disaster)」。九天之后,DeepSeek 用一行 Day 0 公告给出了答案。
「国产替代」这四个字在过去三年里被说滥到失去意义。但 4 月 24 日上午之后,这件事第一次有了可以被资本市场定价的具体数据。单卡吞吐、端到端推理延迟、推理成本、可商用的部署代码,悄无声息地把这场漫长的话术战推到了 production 的门槛之内。
寒武纪股价 11 连阳的逻辑就藏在这里。它不再是一只「国产 GPU 概念股」,而是「DeepSeek V4 推理基础设施供应商」。同样的逻辑也可以解释华虹港股 12% 的涨幅,它代工的是 950PR 的 7nm 等效工艺。每一颗在国产昇腾上跑的 V4 token,都意味着原本要流向英伟达和台积电的产能,被部分截留在了珠江三角洲。
而下一步早已铺好。华为路线图里,950DT(训练版)规划在 2026 年第四季度交付,对应的目标是「V5 或同等量级模型在 1 万卡集群上的全栈训练」。如果这条路能跑通,CUDA 在中国大模型训练侧的护城河,会从「必要」降级为「可选」。


