Vitalik:Eth2分片链简化提案



要点提炼
- 持续性分片链(persistent shard chain)的概念将不复存在,相反,每个分片区块都是直接的交联(crosslink)。提议人发出提案,交联(crosslink)委员会负责批准,一锤定音。
- 分片数量从之前的1024减少到64,分片区块大小从(目标值16,上限值64)kB增加到(目标值128,上限值512)kB。分片总容量为3-2.7 MB/s,具体值取决于时隙。如果需要的话,分片数量和区块大小可随时间的推移而增加,比方说10年后最终达到1024个分片,以及1 MB区块。
- 在L1和L2层实施了诸多简化方案:(i)所需的分片链逻辑更少,(ii)由于“本地”跨分片通信发生在1个时隙内,无需通过Layer2进行跨分片加速,(iii)无需通过去中心化交易所来促进跨分片交易费的支付,(iv) 执行环境能够进一步简化,(v)无需再混合序列化和哈希。
- 主要劣势:(i) 信标链成本更高,(ii)分片区块产生时间更长,(iii)对“突增性”带宽需求更高,但对“平均”带宽的需求更低。
介绍/理念
以太坊2.0目前的架构过于复杂,尤其是在费用市场方面。这个问题由layer 2解决方案引起(针对2.0基础层的重大故障所设计):虽然分片内的区块时间是非常短的(3-6s),然而分片间的基础层通信时间特别长,需要1-16个epoch(如果超过1/3的验证者离线,则会花费时间更久)。这就亟待“乐观”的解决方案:一个分片内的子系统通过某种中等安全的机制(如轻客户端),“假装”提前知道其它分片的状态根,并使用这些不确定的状态根来处理交易,以此来计算自己的状态。一段时间后,所有的分片都将经历“后卫”进程,检查哪些计算使用了其他分片状态的“正确”信息,并抛弃未使用“正确”信息的所有计算。而这个过程是存在问题的,虽然它能够有效地模拟许多情况下的超高速通信时间,但是“乐观”ETH和“真实”ETH之间的差距衍生出了其他复杂情况。具体而言,我们不能假设区块提议者“知道”乐观的ETH,因此,如果分片A上的用户向分片B上的用户发送ETH,则分片B上的用户在拥有协议层ETH(唯一可以用作发送交易费用的ETH)之前,会出现时间延迟。如果想避免延迟,要么需要去中心化交易所(存在复杂性和低效率问题),要么需要中继市场(这将产生垄断中继人对用户进行审查的担忧)。
此外,目前的交联(crosslink)机制大大增加了复杂性,实际上它需要一整套区块链逻辑,包括奖惩计算、单独存储分片内奖励的状态以及分叉选择规则等,这些都需要被纳入分片链中作为阶段1的组成部分。本文档提出了一个大胆的替代方案,用以解决所有这些问题,使以太坊2.0能够更快地投入使用,同时降低风险,其中还有一些折中方案。
方案细节
我们把SHARD_COUNT(分片计数)从1024减少到64,并将每个时隙的分片数上限从16增加到64。这意味着“最优”工作流现在处于每个信标链区块之间,每个分片会产生一个交联(为了清楚起见,我们不再使用“交联”(crosslink)一词,因为并没有“连接”到分片链,直接使用“分片区块”更合适)。
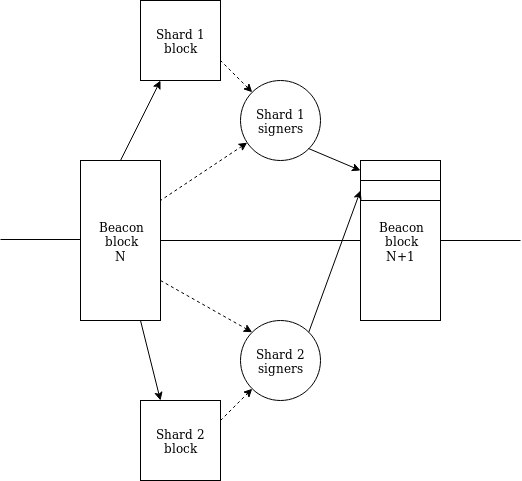
请注意一个关键细节:现在任何分片的slot-N+1区块都可以通过一条路径知道所有分片的所有slot-N 区块。因此,我们现在有了一流的单时隙跨分片通信(通过Merkle收据)。

近似现状

新提案
在这个提议中我们改变了证明所连接对象的结构:不再包含“交联”(crosslink),其中包括以某种复杂序列化形式表示的许多分片区块的“数据根”,而只包含单个区块的数据根,该数据根表示了区块内的内容(内容完全由“提议者”决定)。分片区块还将包括来自提议者的签名。为了促进p2p网络的稳定性,计算提议者的方式依然使用之前基于常设委员会的算法(persistent-committee-based algorithm)。如果没有可用提案,交联委员会成员也可以就“零提案”进行投票。
我们依然在状态中存储一个映射 latest_shard_blocks: shard -> (block_hash, slot) ,不同的是由存储epoch变为时隙。在“乐观情况”下,我们希望这个映射能够更新每个时隙。
将online_validators定义为活跃验证者的子集,活跃验证者即在过去8个epoch中至少有一个epoch包含其证明。如果总数量中2/3的online_validators就给定分片中的新区块达成一致,映射才会进行更新。
假设当前时隙是n ,但对于给定分片i,latest_shard_blocks.slot < n-1(即在前一个时隙中该分片有一个区块跳过),我们则需要该分片的证明来提供范围[latest_shard_blocks.slot + 1….min(latest_shard_blocks.slot + 8, n-1)]内所有时隙的数据根。
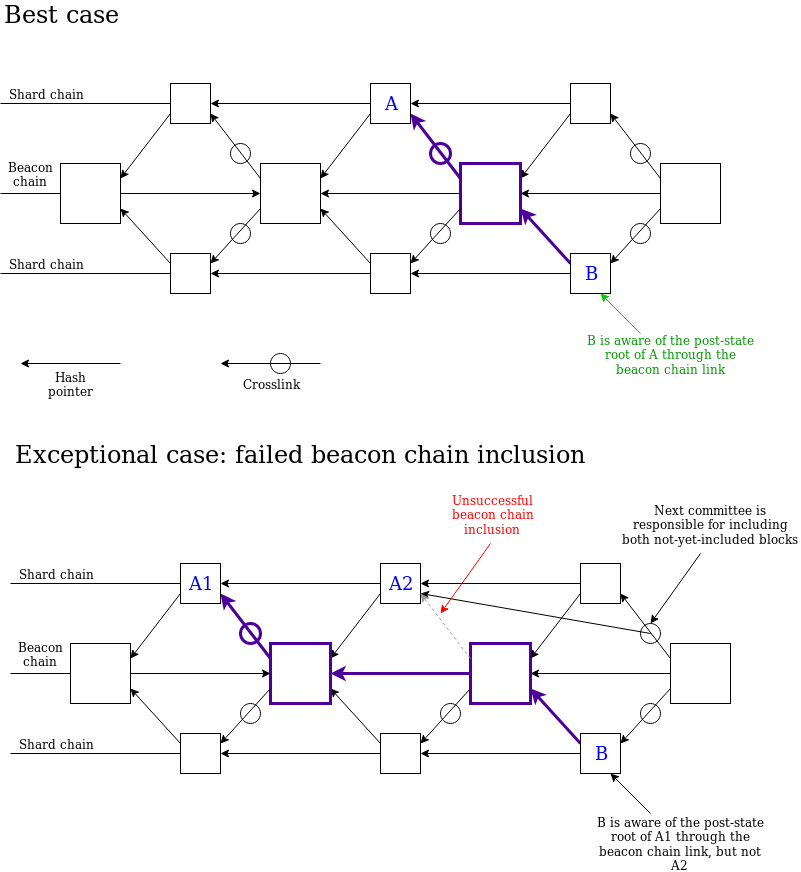
分片区块仍需指向“先前的分片区块”,我们还是要强制保证一致性,因此该协议就要求多时隙证明是一致的。我们推荐委员会采用以下“分叉选择规则”:
- 对于每个有效且可用的分片区块B(该区块的祖先区块也必须有效且可用),计算其最近消息支持B或B的后代的验证者总权重,暂且将该权重称为分片区快B的“得分”。即使是空白的分片区块也可以有得分。
- 为slot + 1选择得分最高的分片区块。
- 为slot + k(k > 1)选择得分最高的分片区块,考虑范围内的区块需要指向latest_shard_blocks[i].slot + (k-1)已经选出的区块。
概述
信标区块N和信标区块N+1之间的发表过程如下:
- 信标区块N发布;
- 对于任何给定的分片i,分片i的提议者提议一个分片区块。执行该区块可见信标区块N和先前区块的根(如果有需要,我们可以将可见性降到区块N-1和旧区块,这使得可以对信标区块和分片区块同时进行提议);
- 映射到分片i的证明者进行证明,包括其对分片i中的时隙 N信标区块和分片区块的意见(在特殊情况中也包括分片i中先前的分片区块);
- 信标区块N+1发布,其中包括所有分片的这些证明。区块N+1的状态转换函数对这些证明进行处理,并且更新所有分片的“最新状态”。
成本分析
请注意,参与者不需要随时主动下载分片区块数据。相反地,提议者发布提议时,只需要在3秒内上传上限为512 kB的数据(假设有400万个验证者,每个提议者平均12.8万个时隙才需要上传一次),随后委员会验证提议时,只需要在3秒内下载上限为512 kB的数据(要求是每个验证者要在每个epoch中下载一次数据,因为我们保留了一个属性:在每个给定epoch的特定时隙中将每个验证者分配给特定交联)。
请注意,此操作的要求低于目前每个验证者的长期负载要求,即每个epoch约2MB。然而,这对“突增性”负载的要求更高:之前是3秒内上限64KB,现在需要在3秒内达到上限512KB。
证明(attestations)负载的信标链数据更改如下。
每个证明有大约300字节的固定数据,加上一个位字段,即每个epoch 400万bit,每个时隙8192字节。因此,目前方案的最大负载为128 * 300 + 8192 = 46592,平均情况中的负载可能更接近32 * 300 + 8192 = 17792,即使这样还可以通过压缩证明中的冗余信息来降低负载。
在本提议中,我们可以看到两种负载(详细参见下文“压缩证明”部分):
- 时隙n的证明将包含在时隙n+1中。我们可以允许包含两个最受欢迎的分片区块/区块头组合,所以就有了128个未经压缩的证明
- 时隙n+1(每个证明约200字节)之后的时隙n中压缩版证明数量最多为128
因此最大负载计算为128 * 300 + 128 * 200 + 8192 = 72192,平均情况负载约为80 * 300 + 10 * 200 + 8192 = 34192。
还要注意的是,证明聚合在每个分片中每个时隙的成本为65536 * 300 / 64 = 307200字节。这为运行节点提供了一个自然的系统需求基础,因此要再压缩区块数据的话也没有什么意义。
从计算层面来说,唯一大幅增加的花销是需要更多的配对(更确切地说,是更多的Miller循环),每个区块的上限从128增加到192,而这将使得区块处理时间延长200ms。
“基础操作系统”分片
每个分片有一个状态,它映射到ExecEnvID -> (state_hash, balance)。一个分片区块被分成一组大块,每个大块指定一个执行环境。一个大块的执行依靠状态根和块的内容(即分片区块数据的一部分)作为输入,并输出 [shard, EE_id, value, msg_hash]元组的一个列表,每个分片最多拥有一个EE_id( 我们添加两个“虚拟”分片:向分片-1的转移表示验证者在信标链支付押金,而向分片-2的转移即向提议支付费用),并且我们从该EE的余额中减去value的总数。
在分片区块头里,我们放置了一个“收据根(receipt root)”,里面包含了一个映射:shard-> [[EE_id, value, msg_hash]…](每个分片最多8个元素;并应该意识到跨分片绝大多数的EE转移是发送到相同的EE,在这种情况下元素的数目甚至更少)。
分片i上的分片区块必须包含一个分片j收据的默克尔分支,而这个分片j是相互分片,该分支位于另一分片的“receipt root”(收据根)(任何分片i都知道任何分片j的收据根)。接收的值被分配给它的EE(执行环境),并且msg_hash对于EE执行是可访问的。
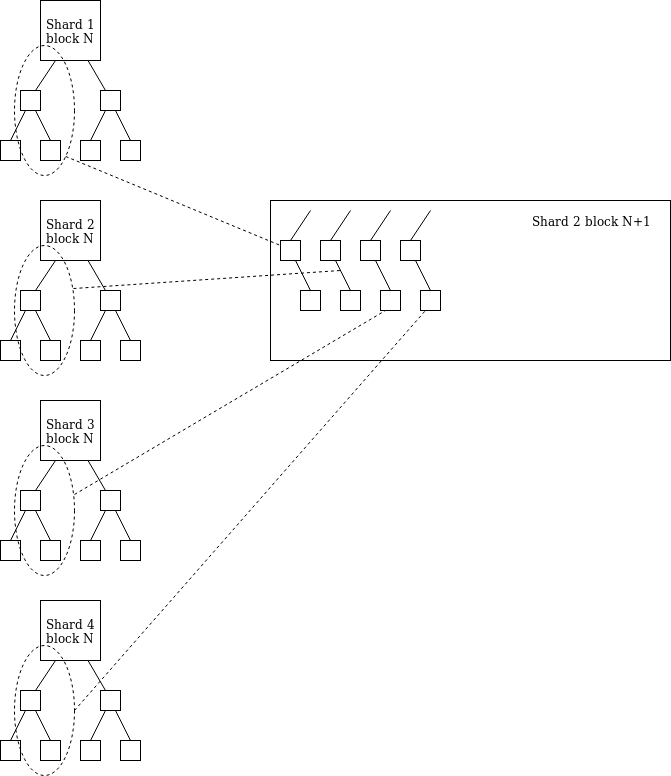
这就允许不同分片之中的EE可以即时进行ETH转移,此时每个分片的成本为(32 * log(64) + 48) * 64 = 15360字节。msg_hash可以被用于减少伴随ETH转移所传递的跨分片信息待验证内容的大小,因此在一个高度活跃的系统里,15360字节数据是必不可少的。
主要 益处 :更简单的费用市场
我们可以接着修改执行环境(EE)系统:每个分片都有一个状态,该状态包含状态根和执行环境的余额。执行环境将能够发送收据,向其它分片的相同EE直接发送货币。这个过程将使用默克尔分支处理机制来完成,每个分片的EE状态储存着一个其余每个分片的随机数,用以抵御重放(replay)攻击。EEs也可以用来直接向区块提交者支付费用。
这提供了足够强大的功能性,使得EEs能够建立在这样的基础之上:允许用户在分片上存币,并将其用以交易费用开支,跨分片上进行这些币的转移,就如在同一分片内进行操作一样简便,从而消除了对中继市场需求的紧迫性,并让EEs承担实施乐观跨分片状态的负担。
压缩证明
出于对效率问题的考量,我们还进行了以下的优化。如前所述,查阅slot n的证明可完整地包含在slot n+1中。但是,如果此种证明内嵌在后续的时隙中,则必须以“精简形式”进行嵌套,仅包含信标区块(头部、对象、源),而不包含任何交联数据。
这样既起到裁减数据的效用,更重要的是,通过强制“旧证明”保存相同数据,可以减少用以验证证据所需的配对数:在大多数情况下,所有来自相同时隙的旧证明都可以经由单一配对验证。如果链不分叉,那么在最坏的情况下,用以验证旧证明的所需配对数会被限制在epoch长度的2倍。如果链确实分叉,则要包含所有证明的能力就得依赖于一个更高的诚实提议者比例(譬如1/32,而非1/64),并且要将更早的证明也包含进去。
保证轻客户端的参与
每天,我们随机选择一个由大约256个验证者组成的委员会,这个委员会可以在每个区块上进行签名,其中签名被包含的验证者便可以在区块n+1中获得奖励。这样做的目的是允许计算能力不高的轻客户端参与。
题外话:数据可用性根
证明一个128 kB数据的可用性的操作是多余的,几乎没有价值。与此相反,有意义的是:要求一个区块能够提供该区块接受并组合在一起的所有分片区块数据的串联根(也许这个分片区块数据根以列表形式存在,其中每个代表64 kB数据,这样使得串联更容易)。 然后可以根据此数据创建单个数据可用性根(平均8 MB,最坏情况下达到32 MB)。 请注意,创建这些根可能要花费比一个时隙更长的时间,因此,最好用于检查一个epoch前的数据的可用性(即,从这些数据可用性根中进行采样将是额外的“确定性检查”)。
其他可能方案
- slotn的分片区块必须查阅slot n-1的信标链区块,而不是slot n。此种措施将允许每个时隙并行循环发生,而不是串联形式,从而减少时隙时间,这样做的代价是导致跨分片通信时间从1个时隙上升到2个时隙。
- 如果一个区块提议者试图将区块大小扩大到64KB以上(备注:目标128kB),他需要首先生成64kB的数据,然后让交联委员会对其进行签名,接着,他们可以添加一个引用第一个签名的64kB数据,以此类推。这将鼓励区块创建者在每隔几秒就可以提交他们区块的部分完成版本,从而创建一种预先确认的机制。
- 加快秘密领导人选举的发展(简单起见,即使一个约8到16人的匿名集环签名版本也能有所作用)。
- 与其使用“强制嵌入”机制,我们不如寻求一个更简单的替代方案:每个分片为其余的每个分片维护一个“传入随机数”和一个“传出随机数”(即8 * 64 * 2 = 1024字节的状态),一个分片制造的收据将需要手动进行添加,并由分片接收者按顺序进行处理。收据生成将受限于每个区块每个目标分片的少数收据,以确保一个分片能够处理所有传入的收据,即使是所有分片同时向它分送收据。


