
Vitalik:分片 + 数据可用性采样



除了 Proof of Stake 之外,eth2 设计中的另外一个显著改变就是分片 (sharding)。本提案介绍了一种分片的有限形式,即“数据分片” (data sharding),根据"以 rollup 为中心的路线图"所述:分片会存储数据,并且证明约 250 kB 数据的可用性。数据可用性验证为 rollups 之类的二层协议提供了安全和高吞吐量的数据层。
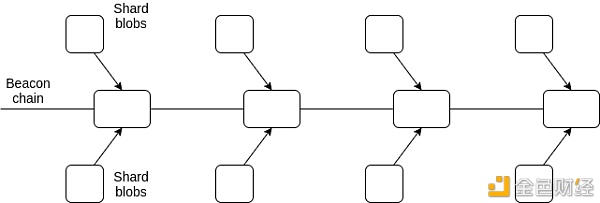
为了免去节点亲自下载全部数据的负担,可以将这两种技术互相叠加起来对大量数据的可用性进行验证: 1) 由随机抽样的委员会提出证明;2) 数据可用性抽样 (data availability sampling, DAS) 。
白话“随机抽样委员会”
假设你有大量数据 ,例如 16 MB,这是 eth2 链 (至少在初期) 每个 slot 能处理的数据量。我们将这些数据表现为 64 个 blobs,每个大小为 256 kB。假设我们还有一个 PoS 系统,验证者数量约为 6400。我们如何在 1) 不需要任何人下载所有数据,2) 不给运行少量验证者的攻击者可乘之机的前提下验证这些数据?
第一个问题,我们可以通过分工来解决:验证者 1-100 需要下载并验证第一个 blob,验证者 101-200 下载并验证第二个 blob,以此类推。每个子集合 (委员会) 里的验证者只需签名证明他们已经验证了相应的 blob,然后整个网络接收到相应委员会中大多数验证者的签名之后,即可接受该 blob。
但这会导致一个问题:万一攻击者控制了连续的验证者集合怎么办 (例如 1971-2070)?如果是这样的话,即使攻击者仅控制了整个验证者集合的约 1.5%,他们也能够控制单个委员会 (在上述情况下,他们可以掌控委员会 20 中 70% 的验证者 2001-2100),因此攻击者能够将无效/不可用的 blob 添加到链上。
随机采样 (Random sampling) 通过随机洗牌算法组成委员会来解决这个问题。 我们使用某个哈希值作为随机数生成器的种子,然后我们使用该生成器来随机混洗验证者列表 1-6400。混洗列表中的前 100 个值是第一个委员会,下 100 个值即为第二个委员会,依此类推。
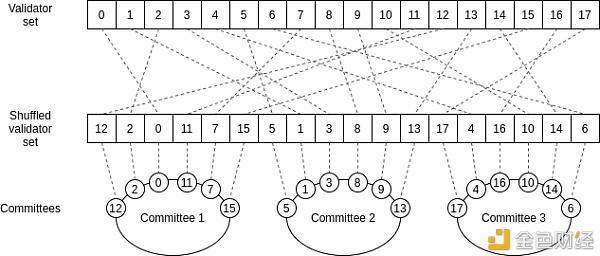
RNG (随机数生成器) 的种子在验证者存款之后选定,每个验证者的索引都是固定的,因此攻击者无法尝试使其所有验证者进入同一个委员会。攻击者可能会走运,但前提是他们控制所有验证者的 1/3 以上。
白话“数据可用性抽样”
在某些方面,数据可用性采样是随机抽样委员会的镜像。仍然会进行采样,这是因为每个节点最终只会下载所有数据的一小部分,但采样发生在客户端中,并且在每个 blob 中进行,而不是在 blob 之间进行。
每个节点 (包括没有参与质押的客户端节点) 对每个 blob 进行检查,他们不需要下载整个 blob,而是私密地从中选择 N 个随机索引,然后尝试在这些位置下载数据。
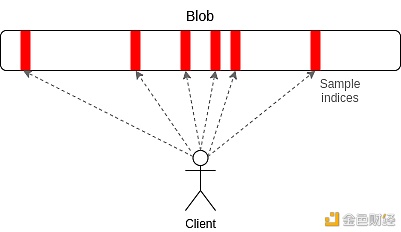
这么做的目的在于验证每个 blob 中至少一半以上的数据是可用的。如果低于一半的数据可用,那么几乎可以认定任何给定客户端进行采样的索引中至少有一个不可用,那么客户端会拒绝接受该 blob。
这个机制是高效的,因为一个客户端只需要下载每个 blob 中的小部分数据以验证其可用性。 这个机制同时也是高度安全的,原因在于即使是 51% 攻击者都无法欺骗客户端接受不可用的 blob。
纠删编码
为了避免攻击者提供了 50-99% 可用数据的情况 (这可能使得某些客户端拒绝某 blob 之后又被其他客户端接受),我们使用了一种叫作 纠删编码 (erasure coding) 的技术。纠删编码使得我们可以使用如下方式对 blobs 进行编码:如果某 blob 中超过一半的数据已经发布,网络中的任何人都可以对剩余数据进行重建和发布。
一旦重新发布的数据广播完毕,起初拒绝该 blob 的客户端会收敛为接受 (注意,接受 blob 没有时间限制,每当客户端收到对其所有抽样索引的响应时,它就会接受可用的 blob)。
理解纠删编码最简单的数学概念类比是“两个点总是足以恢复一条线”:如果我以四个点的形式((1, 4), (2, 7), (3, 10), (4, 13))建立“文件”,每个点都在一条线上,那么只要有其中两个点的坐标,你就能重构这条线,并且将 剩下的两个点计算出来 (我们假设 x 坐标1, 2, 3, 4是系统的固定参数,而非文件创建者的选择)。
使用高阶多项式,我们可以扩展此思想,创建 6 个文件中的 3 个文件,8 个文件中的 4 个文件,或者通常来说 2n 个文件中的n个文件,如果你有文件中的 n个点,则可以计算出 2n 中剩余的点。
默认情况下,一个攻击者也有可能使得没有区块是可用的,并且有选择性地针对其收到的请求发布信息,但这种行为只能欺骗很小一部分客户端,因为攻击者会需要发布一半区块以上来回应所有的请求 (我们假设客户端重新公开广播他们收到的回应)。
我们使用 多项式承诺 (polynomial commitments) ,具体来说是 Kate 承诺而非默克尔根作为数据 blobs 的 printers,因为多项式承诺能够使我们轻易证明一个给定的值实际上是对特定次 n 多项式在所需坐标处的正确估值。不然的话,我们将不得不 (例如使用SNARKs) 证明默克尔根编码一个低次多项式,或者依赖于欺诈证明在编码不正确的情况下进行广播 (这增加了高复杂度以及更多的同步假设)。
有了委员会机制还需要数据可用性抽样吗?
如果只借助委员会的,可能有以下几个劣势:
发生 51% 攻击的时候防御力度较弱。在当前 (不可扩容) 的区块链上,51% 攻击只能回滚交易或是进行审查,并不能向链上添加无效区块。基于委员会的系统会丢失这个保障。
更甚者,要对 51% 攻击者进行有效的惩罚难度会很大,因为他们只有极少量的存款 (参与该特定委员会的存款) 会被证明与恶意行为有关,并在此基础上进行惩罚。
需要一定门槛 (委员会中证明该 blob 的人数达到什么比例才足以将其添加到链上?) 如果这个门槛很高,那么在只有非常少数验证者在线的时候分片的功能会停滞。如果这个门槛过低 (或是某种动态机制,例如按照最近在线验证者数量的比例),那么攻击者可以尝试迫使节点下线来提高他们自己所占的在线验证者比例,从而进行攻击行为。
在抗量子攻击方面,DAS 比委员会机制稍容易些 (可能需要后量子聚合签名)。
有了数据可用性抽样还需要委员会机制吗?
如果只借助 DAS 可能又会产生以下几个问题:
DAS 是一个尚未经过测试的新技术,其核心部分 (参见此处) 其实去年才开发完成。因此在 DAS 崩坏或是开发时间意外延长,使用委员会提供保障是可取的。
DAS 的延迟比委员会高。
DAS 的极端情况更多,委员会可以协助解决。一个例子就是在仅使用 DAS 机制的系统中,很难避免信标区块提议者最早发起 DAS 请求以验证 blob 的可用性。
这会增加攻击者发布不可用 blob 并仅对提议者的请求进行合响应的风险。这不会导致网络的其他节点接受不可用的 blob,但可能会使得其他攻击更为容易,使诚实提议者构建的信标区块被拒绝并从主链上被分叉出去。委员会可以对这一点进行补救。
委员会机制的向前兼容性更强,使得在将来能在分片中加入执行功能。
数据可用性的重要性?挑战又何在?
这已经在别处讨论过了,篇幅有限我就不贴到此处,但我建议阅读:
-
A note on data availability and erasure coding (对数据可用性最初的介绍)
-
Alberto Sonnino、Mustafa Al-Bassam 和 Vitalik Buterin 联合发表的论文对相关概念进行了扩展
-
The Dawn of Hybrid Layer 2 Protocols 对数据可用性中的博弈论进行了论述
-
Base Layers and Functionality Escape Velocity,基于上述概念对数据扩容性部分进行了描述
-
The Data Availability Problem (Ethereum Silicon Valley Meetup),以视频形式对数据可用性问题进行了讨论
有一点需要明确, BitTorrent 和 IPFS 以及类似的系统并没有解决数据可用性问题。 尽管 BitTorrent 是很好的可扩容的数据发布技术,但它不能就是否有可用的数据达成共识,这为一种“极端案例”攻击提供了可能性,在某条数据发布时,节点之间可能发生分歧,使得混合型二层协议无法发挥效用。为了就数据可用性达成共识,需要使用本文档中描述的更强大的技术。
分片如何在 P2P 层上运作?
为了达到分片的扩容性目的,我们需要一个 P2P 系统,这样就无需每个节点都下载所有数据。所幸我们在阶段 0 已经有了一种 P2P 层分片形式。具体来说,有 64 个子集已经用于证明聚合。每个验证者只需要存在于主要的 “整体子网” (global subnet) 和他们自己的证明聚合子网,而无需从其他 63 个聚合证明子集获取任何数据。
在委员会 + DAS 型分片中,我们将其扩展为“网格”架构,有 2048 个 水平子集子网 (horizontal subnets) , 即每 epoch 的每个分片-slot对中存在一个子集,以及 2048 个垂直子网 (vertical subnets) ,即每个 blob 中的每个索引存在一个子集。
在每个 slot 中,我们每个分片都会选出一个提议者。每个提议者都有权提议一个 blob :一个最大为 512 kB 的任意数据块 (我们可以将其理解为约 512 字节的“样本”集合),以及纠删编码扩展和额外的证明,以便对 blob 中的每个部分进行独立验证。
Structure of a blob blob 的结构
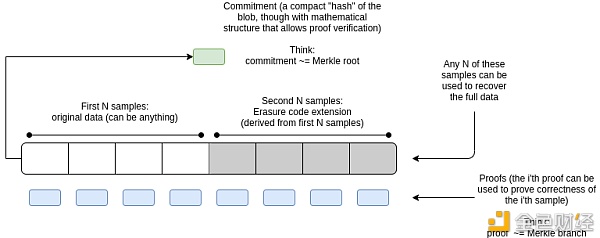
一个 blob 的“主体”结构包括原始数据、扩展数据以及证明 (如果需要的话,为了提高数据效率,可以省略扩展数据,因为接收 blob 的每个节点重建它的速度都相对较快)。
Blob 的“头部”包含其相应的 Kate 承诺,以及其他一些数据 (slot、分片和长度证明) 以及提议者的签名。
Blob 的广播过程
当一个 blob 被广播时,其头部会被广播到整体子网 (global subnet),主体部分则会被广播到相应 slot 和分片 ID 的水平子网。
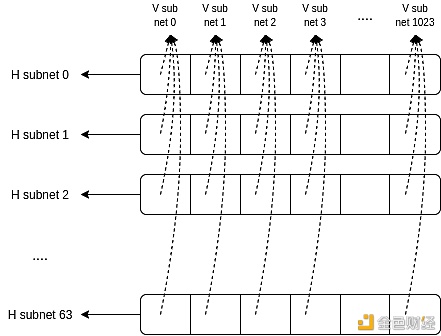
在实际情况中,会存在 2048 个水平子网,以使每个 epoch 中的每个分片-slot对存在对应的一个水平子网。这样做是为了确保每个验证者都可以加入一个水平子网,他们将仅接收到到其所处委员会的相应的 blob (不包括他们参与抽样的少量垂直子网)。
每个验证者都需要加入以下子网:
整体子网 (Global subnet)
水平子网 (horizontal subnet),对应其所处的分片-slot对 (即委员会)
垂直子网 (vertical subnet),对应其分配到的索引 (每个验证者使用私密种子进行计算)
广播区块
Blob 提议者可以将样本分发到所有子网,但不必成为子网的一部分。此过程如下:
发布 :提议者在正确的水平子网中发布 blob,每个样本附带一个证明
直接样本分发 :水平子网中的其他参与者将区块发布到他们所在的每个垂直子网中
间接样本分发 :提议者向对等节点公布几个其所在的垂直子网。因此,水平子网中的每个参与者还可以查看其对等节点所在的垂直子网,并向这些对等节点广播相应的区块
假设数据块大小为 512 字节,且数据 blob 最大为 512 kB (除去纠删编码),在包含纠删编码时约为 1 MB,因此存在 2048 个垂直子网。如果每个节点存在于 15 个私密的垂直子网,5 个公共垂直子网并且有 50 个对等节点,假设在最坏情况下每个水平子网 (仅委员会) 中有128个成员,则单单是子网成员将直接分发到 128 * 20 = 2560 个子网(除去冗余发布后约为 1461),如果加上对等节点,将增加到 128 * 4 * 50 = 25600 个子网。
请注意,从理论上讲,恶意区块提议者有可能在不发布完整区块的情况下将样本发布到垂直子网。为了解决这种情况,我们补充了一个过程,其中未完整发布的区块 (意味着 50% 及以上可用,但不是 100% 可用) 能够进行“自我修复”。该过程包括三个基本步骤:
1. 反向分发 :与上述分发过程相同,只是在这种情况下,垂直子网上的对等节点将样本从该垂直子网上传播到与该样本所属 blob 相对应的水平子网。
2. 重构: 如果水平子网中有 1024 及以上个样本 (或者通常来说样本总量的一半),任何人都可以重构整个 blob,然后向水平子网发布其重构后的 blob。
3. 分发: 重复上述的分发步骤
信标链如何工作?
在每个 slot 中,我们为 64 个分片中的每个分片随机选择一个提议者。提议者有权创建一个分片 blob,并通过上述过程对其进行广播,并且将该 blob 的 ShardHeader 广播到全局子网。ShardHeader 能够被打包到信标链上的同个 slot 中,也可以包含在同个/下个 epoch 中的任何后续 slot 中。
信标链会跟踪 PendingShardHeader 的对象列表。PendingShardHeader 会存储:1) ShardHeader 中的关键信息 (分片和 slot,该 blob 的承诺及其长度);2) 追踪随机选择的委员会中哪些验证者在 blob 中签名的位域 (实际上就是阶段 0 已经引进的委员会)。AttestationData 结构扩展为包含一个 shard_header_root,即选定验证者进行投票的 ShardHeader 的根哈希。如果证明者看不到已分配给他们的分片-slot对的有效且可用的分片 blob,则他们也可以对空的根哈希进行投票。
如果 ShardHeader 得到了委员会中 2/3 验证者的证明,就会 立即得到确认 。如果在下一个 epoch 结束时,ShardHeader 得到委员会的支持比其他任何 ShardHeader 更多的支持,则在该 epoch 结束时进行确认。
分叉选择规则
分叉选择规则发生了改变,以便仅在该区块中确认所有 blob 或其祖先都通过了可用性检查的情况下,该区块才有效。这称为 紧密耦合 (tight coupling) :如果一条链指向 (已确认) 某个无效 blob,则整条链都被视为无效。这是与“侧链”结构的主要区别:在侧链中,侧链可能会失效,而主链仍然有效。
这里有对紧密耦合的进一步探索,以及为什么它是有价值。
验证者数量较低的情况
如果验证者少于 262144 个(32 slots* 64 shards* 128 最小委员会规模),那么我们不再为所有分片选择一个提议者,而是为一个有限的子集选择一个提议者,循环遍历这些分片。比如说,如果有 32 * 128 * 50 个验证者,在 slot N 的起始分片为 0,则 slot N 将为分片 0-49 分配一个提议者,slot N + 1 将为分片 50-63 和 0-35 分配一个提议者,slot N + 2 将为分片 36-63 和 0-21 分配提议者,依此类推。这样做是为了确保即使在参与度较低的情况下,委员会的规模仍然足够。
分片数据的 gas 费
添加了一种类似于 EIP-1559 的机制,按字节计费分片数据,并对价格进行了调整:如果区块的平均容量超过了 50%,则提升费用,反之则降低。因此,指标是 50% 的平均区块大小。
安全假设
仅支持数据 blob 的分片之所以强大,是因为与其他分片方案相比,它对安全性假设的依赖性很低。尤其是它避免了诚实的大多数假设 (因为 DAS 可以检测到由大多数发布的不可用 blob) 和时间假设 (与早期的 DAS 机制不同,其使用的是 Kate 承诺而非欺诈证明,因此不依赖于欺诈证明需要极快被广播的假设)。
恶意的 51% 联盟可以对 blob 进行审查,但是在非分片链中也可以进行 51% 审查。
主要的新假设是“诚实的少数 DAS 假设”:存在足够多的节点样本,攻击者必须要发布区块中一半以上的内容。如果一个 blob 中有 2048 个样本,则需要恢复 1024 个样本 (考虑到某些客户端将对相同的点进行抽样,因此 2048 * ln(2)~= 1419),并且每个客户端都进行 20 个采样,则如果每个分片有约超过 70 个客户端在进行抽样的话就可以认定系统是安全的。
向前兼容性
仅支持数据 blob 的分片设计与以后在分片中添加执行的许多方案具有向前兼容性。特别是我们可以对该方案进行修改以使 blob 包含前状态和后状态根,我们还可以使用欺诈证明或 ZK-SNARK 来验证 blob 中的状态转换是否正确。注意,无论选择哪种方法,确保分片执行的正确性都不依赖于任何诚实大多数假设。
Github PR 链接
https://github.com/ ethereum /eth2.0-specs/pull/2146


