


据《The Information》报道,OpenAI 已经着手研发一款能够从文本或音频提示生成音乐的人工智能模型,并与 Juilliard 音乐学院的学生合作,对乐谱进行注释以充当训练数据。这一动向意味着 OpenAI 将把生成式能力从文本与视频进一步拓展到音乐领域,相关产品形态与上线时间尚未明确。

图源:网络
该工具的目标使用场景包括为现有视频自动配乐、为人声生成吉他等伴奏,交互方式支持文本与音频提示,产品形态既可能独立发布,也可能整合到 ChatGPT 或 Sora 中。就应用范围而言,预期覆盖广告短曲、视频背景音乐到完整作品等多层级制作需求。
从竞争格局看,OpenAI 的入局将直接对标当前市场上更早布局生成音乐的 Suno、Udio 等公司,亦与 Google 等科技巨头的相关尝试形成对比。考虑到 OpenAI 拥有庞大的 ChatGPT 用户基础,音乐生成能力若能与其生态深度融合,势必增强平台黏性与商业化想象空间。
法律与伦理层面,行业对训练数据来源与版权合规的警惕持续升温。唱片公司已就训练材料的版权问题起诉 Suno 与 Udio 等生成音乐平台,凸显许可、分成与创作者权益的关键性挑战。OpenAI 若推进相关产品,也将面临类似的许可与风控议题。
OpenAI 并非首次涉足音乐生成:2019 年推出 MuseNet,2020 年发布早期实验项目 Jukebox,此后阶段性淡出该领域。此次重启音乐生成路线,既延续其多模态模型演进,也反映生成式 AI 向更多创意生产环节渗透。
英特尔 Q3 扭亏为盈:净利润 41 亿美元,去年同期亏损 166 亿美元
英特尔在 2025 年第三季度实现近两年来首次盈利,营收与多项关键指标好于市场预期,显示出在成本收缩与资本加持下的阶段性修复迹象。公司披露第三季度营收约 136.5 亿美元,超过 LSEG 市场一致预期的 131.4 亿美元;按非 GAAP 口径每股收益为 0.23 美元,但由于与美国政府入股相关的托管股份会计处理,该数据不具可比性。英特尔报告净利润 41 亿美元,较去年同期 166 亿美元亏损大幅好转。

图源:英特尔
资本层面,英特尔在过去两个月获得多项外部支持,包括美国政府在 8 月以约 89 亿美元取得公司 10% 股权,成为第一大股东;英伟达在 9 月以 50 亿美元入股并推进 CPU 与 AI GPU 的协同方案;软银在 8 月注资 20 亿美元。公司同时通过出售 Altera 与 Mobileye 等资产充实现金,管理层称由此提升了资产负债表韧性与战略执行灵活性。
业务结构上,客户端计算业务营收约 85 亿美元,同比增长,受 Windows 10 进入生命周期末期、企业与消费者换机需求加速影响;数据中心 CPU 业务约 41 亿美元,同比小幅下滑。管理层指出,随着 AI 应用从试验走向生产,推理负载对 CPU 的需求提升,叠加超大规模客户更新老旧服务器,后续数据中心 CPU 需求有望回暖。
供应与产能方面,英特尔坦言当前供给紧张,预计明年一季度短缺将达峰,短期将优先保障服务器与 AI 相关产品的产能与出货,并对价格与产品结构进行动态调整。面向客户端的 Panther Lake(基于 Intel 18A 工艺)今年仅推出一个 SKU,更多型号将在 2026 年逐步放量。公司称 18A 产能与良率“足以满足供应”,但尚未达到支撑理想毛利的水平;18A 将作为“长生命周期节点”,支撑至少三代客户端与服务器产品。与此同时,下一代 14A 节点在客户推动下进展“优于同阶段的 18A”,英特尔表示对其更有信心。公司并计划每年发布新一代 AI GPU,以适应爆发式的服务器需求。
英特尔代工(Foundry)业务仍是转型成败的关键。该业务本季度营收约 42 亿美元、同比下降 2%,当前收入主要来自公司自用生产。美国政府的投资条款要求英特尔未来五年不得剥离代工业务。英特尔表示已在亚利桑那启动最先进工艺芯片生产,并与潜在客户积极接触,但强调“纪律性增长”,通过流程与客户生态的适配来建立长期信任。
费用与组织方面,英特尔持续推进降本增效,季度末员工总数降至约 8.84 万名,较去年同期减少约 29%。展望第四季度,公司给出营收指引区间 128–138 亿美元,中位数约 133 亿美元,与市场预期大致匹配,非 GAAP 每股收益指引约 0.08 美元。管理层提示,因政府入股的复杂会计处理尚待监管确认,财务结果未来可能调整。
高通发布 AI200 与 AI250 数据中心推理加速器
在 AI 数据中心竞赛升温之际,高通宣布推出面向推理场景的两款加速器芯片 AI200 与 AI250,并配套整机机架与加速卡形态,计划分别于 2026 年与 2027 年商用。新产品基于高通长期在移动与 PC 领域使用的 Hexagon NPU 技术,定位于以更优的“性能 / 成本 / 功耗”比,服务大规模生成式 AI 推理。

图源:高通
高通表示,AI200 单卡支持 768GB LPDDR 内存,强调以更高容量、较低成本满足大参数量与多模型并行的推理需求;机架方案采用直液冷散热、PCIe 横向扩展与以太网纵向扩展,并引入机密计算以实现内存分区加密,机架级功耗为 160kW。AI250 则将采用“近存储计算”的创新内存架构,宣称相较 AI200 能提供超过 10 倍的有效内存带宽,同时显著降低功耗,面向更高密度与更低能耗的推理集群。
高通此次布局聚焦推理而非训练,意在切入企业从试点走向规模化生产的关键阶段。推理工作负载的经济性正在成为竞争焦点,企业愈发以每 Token 成本、每 Token 能耗、内存容量密度与延迟 SLA 等指标做决策。在这一背景下,强调能效与内存规模的非 GPU 加速器正争夺特定推理层级的份额。
从生态与产品形态看,AI200 与 AI250 将以可加装至现有服务器的加速卡形式提供,降低存量机房的改造门槛;软件方面,高通称其推理导向的完整栈兼容主流 AI 框架,并支持一键部署 Hugging Face 模型与推理优化技术。市场层面,沙特的 Humain 已宣布将从 2026 年起部署高通机架解决方案,目标在本地与全球提供高性能推理服务。
尽管发布信息尚未披露具体算力、功耗曲线与核心架构细节,且 AI250 定档 2027 年使得对其竞争力的全面评估仍需时间,但在英伟达、AMD 之外,推理芯片供应的多样化趋势正在形成。
AMD 与美国能源部合作,将斥资 10 亿美元打造两台 AI 超级计算机
AMD 与美国能源部(DOE)宣布达成总额 10 亿美元的合作,将在田纳西州橡树岭国家实验室(ORNL)建设两台新一代超级计算机,分别命名为 Lux 与 Discovery,用于加速从核能与聚变研究到癌症治疗、国家安全等多领域的重大科学任务。

图源:ORNL
Lux 预计最快在未来六个月内上线,时间窗口约为 2026 年初;更先进的 Discovery 计划于 2028 年交付、2029 年投入运行。此次项目由 DOE 承载场地与运营,AMD、HPE 与 Oracle 等伙伴提供设备与资本开支,政府与企业将共享算力资源。
两台新机均以 AMD 技术为核心:Lux 采用 MI355X 人工智能加速芯片,并整合 AMD 的 CPU 与网络芯片,ORNL 主任 Stephen Streiffer 表示其 AI 能力约为当前超算的 3 倍;而 Discovery 将基于 MI430 系列,面向高性能计算与 AI 的融合工作负载,强调“Bandwidth Everywhere”的架构理念,在与 ORNL 的 Frontier(曾为全球最快超算)同等成本下提升性能与能效,并支持与 Frontier 的工作负载兼容迁移。
合作方强调该项目的科学使命与应用落地。能源部长 Chris Wright 称两台系统将“超级加速”核能、聚变、国防与药物研发等关键领域;他对聚变前景表达乐观,认为借助 AI 与超算的推进,有望在两到三年内探索出可行的“实用路径”;同时希望在五到八年内将多数癌症从“终极绝症”转变为可管理疾病。
英伟达 GTC DC 全面发力:量子—经典互联、AI 超级计算机、数据中心“操作系统”齐上阵
10 月 28 日,在华盛顿举办的 GTC DC 上,英伟达以“全栈”路线同时推进科研、企业与政府的 AI 基础设施:与美国能源部及 Oracle 共建七台 AI 超级计算机;推出连接量子处理器与 GPU 超算的新型互联 NVQLink;发布面向数据中心的 BlueField‑4 DPU;并与 Palantir、HPE 等深化合作,将 AI 从研发推向运营与合规落地。这一系列产品将被为美国下一轮工业与科学复兴提供充实的算力基础。
首先,英伟达与美国能源部、甲骨文合作将于伊利诺伊州阿贡国家实验室部署两阶段 AI “工厂”:第一阶段的 Equinox 将配备 10000 个 Blackwell GPU,第二阶段 Solstice 规模扩至 100000 个,二者互联后合计可达约 2200 exaFLOPs 的 AI 计算性能,用于前沿模型与“代理型科学家”研发,提升公共科研生产率。Equinox 预计 2026 年上线,Solstice 时间未定。

图源:英伟达
在洛斯阿拉莫斯国家实验室,英伟达与 HPE 将基于下一代 Vera Rubin 平台建设两台新系统 Mission 与 Vision:前者面向国家核安全局的保密仿真任务,后者服务于公开科学与 AI 研究,二者计划于 2027 年投入运行,延续并超越该实验室 Venado 的开放科研成果。此举显示 Rubin 平台在保证 AI 低精度推理能力的同时,不牺牲高性能计算的 FP64 科学计算吞吐。

图源:英伟达
量子方向上,英伟达发布的 NVQLink 被定位为量子—经典超算“罗塞塔石”:通过低时延、高吞吐的开放互联,将量子处理器 QPU 与 GPU 超算深度耦合,以满足量子误差校正、标定与控制算法对经典计算的严苛实时性需求,并已与多家量子硬件商及美国多所国家实验室协同研发,未来混合式量子—经典架构有望成为科研标配。

图源:英伟达
数据中心“操作系统”层面,BlueField‑4 DPU 集成 64 核 Grace CPU 与 ConnectX‑9 SuperNIC,面向 Spectrum‑X 以 800Gb/s 吞吐加速网络、存储与安全等基础设施任务,相比 BlueField‑3 计算力提升约 6 倍,并通过 DOCA 微服务实现多租户网络、快速数据访问与 AI 运行时安全,目标是在 2026 年随 Vera Rubin 平台率先早期供货。该产品将 GPU 算力专用于训练/推理,把数据搬运、协议栈与零信任安全下沉至 DPU,从而提升整场景效率与可控性。
面向政府与受监管行业的合规部署,HPE 宣布与英伟达扩展“AI Computing by HPE”组合,推出第二代小型化 HPE Private Cloud AI,采用 ProLiant DL380a Gen12 与 RTX PRO 6000 Blackwell Server Edition,实现基于 MLPerf 的三倍价格—性能提升,并提供“空气隔离”管理选项满足数据主权与隔离要求;其统一数据层结合 Alletra Storage MP X10000 与与英伟达协作开发的 S3oRDMA,显著降低延迟与 CPU 占用,并支持在离线环境运行。HPE 亦推出面向超大模型的 GB300 NVL72 by HPE 与支持 8× Blackwell Ultra B300 GPU 的 ProLiant XD685,通过液冷与整机架 NVLink 提供千兆级参数规模训练能力。
总体看,本次 GTC DC 的核心信号是:英伟达正以开放互联、参考设计与软件栈贯通量子、超算、数据中心与行业运营,将“AI 工厂”从单点算力建设升级为跨算力形态、跨数据域、可治理且可运营的系统工程。
英伟达斥资 10 亿美元入股诺基亚,携手推进 6G 网络
10 月 28 日,英伟达(Nvidia)宣布以约 10 亿美元认购诺基亚(Nokia)新发行股份,双方同时达成战略合作,将在无线网络设备与数据中心网络领域深度整合双方的加速计算技术、AI 能力、光纤通信技术,以推动从 5G‑Advanced 向 6G 的演进与 AI 原生网络落地。

图源:英伟达
根据披露条款,英伟达将认购诺基亚新发行的 1.66 亿股,认购价每股 6.01 美元,交易完成后英伟达将持股约 2.9%。受消息提振,诺基亚股价当日一度上涨逾两成,创多年最大涨幅。
此次合作的核心聚焦于将 AI 引入无线接入网(AI‑RAN)以提升频谱与能效,同时在同一加速化平台上统一 AI 与 RAN 工作负载,支持更低时延的边缘推理。英伟达同步发布面向电信的 6G‑ready 加速计算平台 Aerial RAN Computer Pro(ARC‑Pro),并称诺基亚将把其 5G 与 6G 软件适配至 CUDA 平台并将 ARC‑Pro 嵌入新一代 AI‑RAN 方案。双方还计划在数据中心交换与以太网方面合作。
OpenAI 完成公司重组,微软持股 27%
在监管审查与长达一年多的谈判后,OpenAI 宣布完成公司重组:其营利实体重组为公共利益公司 OpenAI Group PBC,非营利主体更名为 OpenAI Foundation 并继续控股营利公司。重组同步落地的与微软的新协议,明确了双方在 2032 年前的技术与知识产权安排,并引入独立专家评审机制来验证何时达到 AGI。

图源:微软
新协议下,微软在 OpenAI Group PBC 中持有约 27% 股权,账面价值约 1350 亿美元,并保留对 OpenAI 模型与产品的独家知识产权直至 2032 年(含 “post‑AGI” 模型,配套安全护栏);对研究方法的知识产权则最迟延续到 2030 年或专家组确认达到 AGI 之时,以先到者为准。与以往不同的是,AGI 的宣布不再由 OpenAI 单方认定,需经独立专家核验,这一机制将决定双方收入分成与研究 IP 权利的截止点。微软的权利明确不涵盖 OpenAI 的消费级硬件。双方也放宽了互相排他:OpenAI 可与第三方联合开发部分产品(API 类需部署在 Azure,非 API 类可选择任意云),微软则可独立或与第三方探索 AGI。OpenAI 同时承诺额外采购 Azure 服务总计 2500 亿美元,但微软失去对其算力采购的优先拒绝权。
从资本与治理看,重组后 OpenAI Foundation 持有营利公司约 26% 股权,当前估值约 1300 亿美元,并在达到特定估值里程碑后享有额外认股权。基金会宣布首期 250 亿美元投入两大方向:健康与治愈疾病,以及面向 AI 的技术性韧性与风险最小化举措;董事会层面保留对营利公司安全工作的监督。
尽管协议细节较为全面,外界仍关注两点悬而未决:其一,独立专家的组成人选与 AGI 验证标准尚未公开;其二,OpenAI 计划推出的消费级硬件如何与现有生态衔接,而该硬件明确被排除在微软的 IP 权利之外。
英伟达成为全球首家市值 5 万亿美元公司
美国芯片巨头英伟达(Nvidia)周三盘中与收盘双双站上 5 万亿美元市值关口,创下全球上市公司历史新高。受此带动,科技股集体走强,苹果、微软近期也相继触及或重返 4 万亿美元市值区间。此次里程碑出现在今年以来英伟达股价大幅攀升的背景下,年内累计涨幅已超过 50%。

图源:Yahoo Finance
市场情绪的快速升温与英伟达在华盛顿举办的 GTC 大会密切相关。首席执行官黄仁勋宣布,到 2026 年底公司对 Blackwell 与 Rubin 两代 AI 加速器的累计订单“可见度”已达 5000 亿美元,并与美国政府合作建设 7 座超算中心。此外,英伟达公布与 Uber 的自动驾驶车队合作、与 Palantir 的企业 AI 协作、向制药企业 Eli Lilly 提供 1000 块 GPU,以及出资 10 亿美元入股 Nokia 以推动 6G 网络与通信设备的本土化;公司还发布面向量子计算的 NVQLink 开放架构,连接量子芯片与 GPU 以加速误差校正与应用落地。这些举措帮助投资者强化对英伟达长期收入与生态版图的信心。
受美国出口管制影响,英伟达当前在中国大陆的高端 AI 芯片销售几近停摆,但美国总统唐纳德·特朗普表示将与黄仁勋讨论 Blackwell 芯片对华出口的可能性;此前有关对中国销售按营收比例分成 15% 的许可安排仍待立法落实。若对华市场部分重启,有望为英伟达的订单与收入带来额外上行空间。
SK 海力士三季度创纪录盈利,明年 HBM 及存储产能已售罄
SK 海力士在 AI 浪潮带动下业绩飙升,近日公司披露 2025 财年第三季度营业利润达 11.4 万亿韩元,同比大增 62%,创历史新高;营收 22.4 万亿韩元,同比增长 39%。受面向 AI 数据中心的高带宽内存 HBM 及高性能 DRAM、企业级 eSSD 需求驱动,产品结构与价格同步改善。

图源:网络
公司表示,随着 AI 应用从训练转向推理,服务器侧对高性能内存的需求持续升温,HBM 供需紧张将难以在短期内缓解。SK 海力士已与主要客户完成明年 HBM 供应谈判,预计今年第四季度开始供应 HBM4,并在明年扩大销售。管理层称“明年包括 DRAM、NAND 与 HBM 在内的产能基本售罄”,部分客户已提前锁定 2026 年常规存储产品。
在资本规划方面,SK 海力士将“实质性增加”投资,通过 M15X 等项目加速先进工艺转换、扩充产能,以应对超预期的客户需求。公司估计 AI 大型项目(包括与 OpenAI 的预协议)带来的 HBM 内存需求将超过当前行业总产能的两倍,并将建立相应的生产体系以满足订单。
行业层面,咨询机构数据显示 SK 海力士在全球 HBM 市场份额过半,三星与美光加速追赶;分析师普遍预计 HBM 市场未来几年将保持高增,供不应求态势或延续至 2027 年。同时,AI 推动的高性能芯片生产挤占传统内存产能,DRAM 与 NAND 价格与出货回暖。受利好刺激,SK 海力士股价年内已大幅上涨。
Cursor 发布 2.0 版本与自研编码模型 Composer
10 月 29 日,AI 编码平台 Cursor 推出重大更新:发布自研编码模型 Composer,并上线以代理为中心的 Cursor 2.0 版本。

图源:Cursor
Composer 旨在低延迟的代理式编码场景下保持前沿智能与高速响应,声称较同等智能模型速度提升约 4 倍,绝大多数任务在 30 秒内完成。Composer 通过覆盖整个代码库的语义搜索等工具进行训练,强化对大型与复杂代码库的理解与导航能力;其架构为混合专家 MoE,并在多样化开发环境中通过强化学习进行后训练,支持长上下文生成与推理。
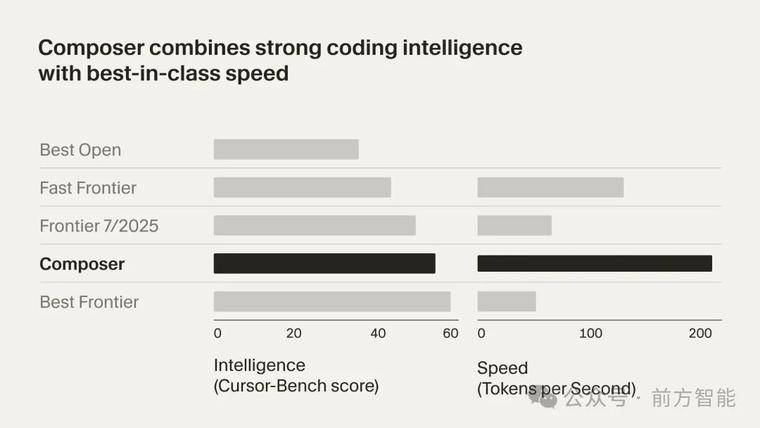
图源:Cursor
Cursor 2.0 在产品形态上转向“以代理为中心”,支持并行运行多个代理,底层由 git worktree 或远程机器隔离工作空间,便于同时比较不同模型输出并择优采用。在工程工作流上,该版本针对“代码评审”和“变更测试”两大瓶颈提供原生支持:集成浏览器工具以便代理自动运行与测试代码、聚合多文件 diff 以加速审阅,并可在需要时深入代码细节。这一组合旨在让代理从规划、编写到测试与修复更趋自动化,提升复杂多步骤任务的端到端完成度。
Cursor 表示 2.0 现已开放下载,继续支持多家第三方前沿模型,同时以 Composer 作为快速、可靠的代理式编码核心,面向专业团队的并行协作与高效审查测试场景。


