原文作者:KarenZ,Foresight News
2026 年 3 月 20 日,All-In 创投播客里有一幕并不寻常的对话。
风投大佬 Chamath Palihapitiya 把话头递给了英伟达 CEO 黄仁勋,说 Bittensor 上有个项目「完成了一件相当疯狂的技术成就」,用分布式算力在互联网上训练了一个大型语言模型,过程完全去中心化,没有任何中心化的数据中心参与。
黄仁勋没有回避。他把这件事对标到 「Folding@home 的现代版本」 ,那个在 2000 年代让普通用户贡献闲置算力、共同对抗蛋白质折叠难题的分布式项目。
在此之前的 4 天前,3 月 16 日,Anthropic 联合创始人 Jack Clark 在发布一期 AI 研究进展报告中,也用大量篇幅重点介绍和引用这项突破:Bittensor 生态子网 Templar(SN3)完成 720 亿参数大模型(Covenant 72B)的分布式训练,模型性能与 Meta 2023 年发布的 LLaMA-2 相当。
Jack Clark 为该章节命名为「通过分布式训练挑战 AI 政治经济学」,并在分析中强调,这是一项值得持续追踪的技术——他能想象一个未来:设备端 AI 大量采用去中心化训练产出的模型,而云端 AI 则继续运行专有大模型。
市场的反应略微滞后但非常剧烈:SN3 过去一个月涨逾 440%,过去两周涨逾 340%,市值达到 1.3 亿美元。子网的叙事爆发,会直接传导为 TAO 的购买压力。也因此,TAO 快速上涨,一度达到 377 美元,过去一个月翻倍,FDV 达到约 75 亿美元。
问题来了:SN3 到底做了什么?为何会被推至聚光灯下?分布式训练和去中心化 AI 的价值叙事又将如何演变?
那个 72B 的模型
要回答这个问题,得先看清楚 SN3 交出的成绩单。
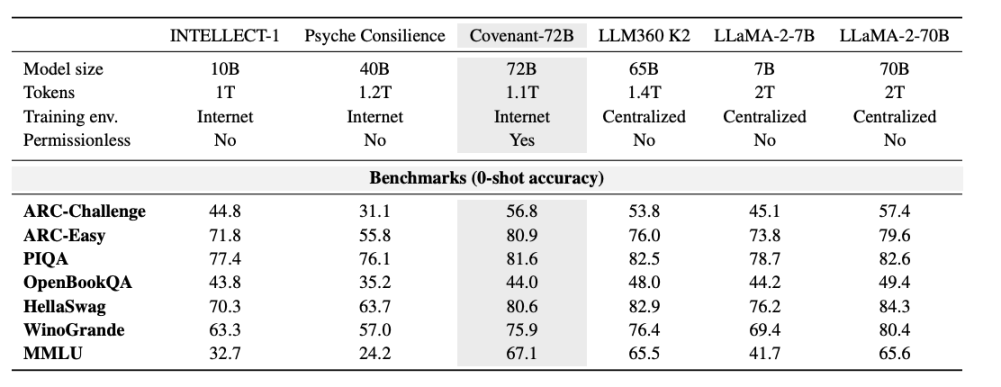
2026 年 3 月 10 日,Covenant AI 团队在 arXiv 上发布了一篇技术报告,正式宣告 Covenant-72B 完成训练。 这是一个 720 亿参数的大型语言模型,超过 70 个独立节点 peers (每轮约 20 个节点同步,每个节点配备 8 张 B200), 在约 1.1 万亿 tokens 的语料上完成了 720 亿参数模型的预训练。
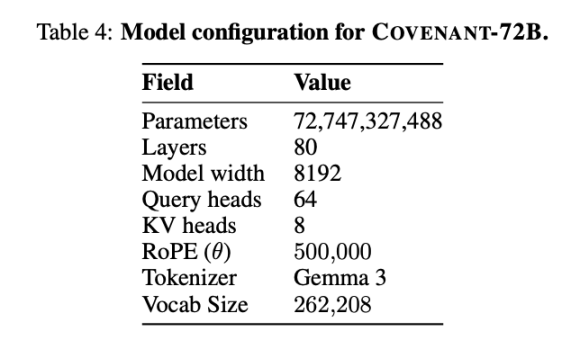
Templar 给出了在基准测试方面的一些数据,当然,对比的 LLaMA-2-70B 为 Meta 在 2023 年发布的大模型。 正如 Anthropic 联合创始人 Jack Clark 所说,Covenant-72B 放在 2026 年可能有些过时了。 Covenant-72B 在 MMLU 上的 67.1 分,大致对标的是 Meta 2023 年发布的 LLaMA-2-70B(65.6 分)。
而 2026 年的前沿模型——无论是 GPT 系列、Claude 还是 Gemini——早已在数十万块 GPU 上完成了参数量远超 1000 亿的训练,推理、代码、数学能力的差距是数量级而非百分比的问题。这个现实差距不应该被市场情绪淹没。
但换算到「用开放互联网上的分布式算力训练出来」这个前提下,意味就完全不同了。
来做个比较:同为去中心化训练的 INTELLECT-1(Prime Intellect 团队出品,100 亿参数)MMLU 得分 32.7;另一个在白名单参与者中进行的分布式训练项目 Psyche Consilience(400 亿参数)得分 24.2。Covenant-72B 以 72B 的规模、67.1 的 MMLU 分数,在去中心化训练赛道中是个显眼的数字。
更关键的是,这次训练是「无需许可」的。任何人都可以接入成为参与节点,不需要事先审核,不需要白名单。超过 70 个独立节点参与了模型更新,从全球各地连接贡献算力。
黄仁勋说了什么,没说什么
还原一下那场播客对话的细节,有助于校正外界对这次「背书」的解读。
Chamath Palihapitiya 在对话中把 Bittensor 的技术成就呈现给黄仁勋,并描述为用分布式算力训练了一个 Llama 模型,过程「完全分布式,同时保持状态」。黄仁勋的回应是把这比作「现代版的 Folding@home」,并展开讨论了开源与专有模型并行共存的必要性。
值得注意的是,黄仁勋没有直接提到 Bittensor 的代币或任何投资含义,也没有进一步讨论去中心化 AI 训练。
理解 Bittensor 子网和 SN3
要理解 SN3 的突破,首先需明确 Bittensor 及其子网的运作逻辑。简单来说,Bittensor 可看作是一条 AI 公链和平台,而每个子网就相当于一条独立的「AI 生产流水线」,各自明确核心任务、设计激励机制,协同构成去中心化 AI 生态。
其运作流程清晰且去中心化:子网所有者定义子网目标并编写激励模型;矿工在子网中提供算力、完成 AI 相关任务(如推理、训练、存储等);验证者对矿工的贡献进行打分,并将评分上传至 Bittensor 共识层;最终,Bittensor 的 Yuma 共识算法会根据各子网累积的奖励,向子网参与者分配相应收益。
目前 Bittensor 上有 128 个子网,覆盖推理、无服务器 AI 云服务、图像、数据标注、强化学习、存储、计算等各类 AI 任务。
而 SN3 就是其中的一个子网。它不做应用层套壳,不租用现成的大模型 API,而是直接瞄准了整个 AI 产业链里最贵、最封闭的核心环节之一:大模型预训练本身。
SN3 希望利用 Bittensor 网络协调异构计算资源的分布式训练,通过激励式分布式大模型训练,证明无需昂贵的中心化超级计算机集群,同样可以训练出强大的基础模型。核心吸引力在于「平权」——打破中心化训练的资源垄断,让普通个体或中小机构也能参与大模型训练,同时借助分布式算力降低训练成本。
推动 SN3 发展的核心力量是 Templar,其背后的研究团队为 Covenant Labs。 该团队还同时运营着另外两个子网:Basilica(SN39,专注计算服务)和 Grail(SN81,专注 RL 后训练与模型评估)。三个子网形成垂直整合,完整覆盖了大模型从预训练到对齐优化的全流程,构建起去中心化大模型训练的完整生态。
具体而言,矿工贡献计算资源,将梯度更新(模型参数的调整方向和力度)上传至网络;验证者评估每位矿工的贡献质量,按照误差改善幅度给予链上评分。结果决定奖励权重,自动分配,无需信任任何第三方。
激励机制设计的关键是,奖励直接挂钩「你的贡献让模型变好了多少」,而非单纯的算力出勤。这就从根本上解决了去中心化场景中最难的问题:如何防止矿工摸鱼。
那 Covenant-72B 如何解决通信效率和激励相容问题?
让几十个互不信任、硬件各异、网络质量参差不齐的节点协同训练同一个模型,挑战有两个:一是 通信效率 ,标准的分布式训练方案要求节点间高带宽、低延迟的互联;二是 激励相容 ,如何防止恶意节点提交错误的梯度?如何确保每个参与者都在老老实实训练,而不是抄袭他人的结果?
SN3 用两个核心组件解决了这两个问题: SparseLoCo 和 Gauntlet 。
SparseLoCo 解决通信效率问题 。传统的分布式训练每一步都要同步完整梯度,数据量巨大。SparseLoCo 采用的方案是:每个节点在本地跑完 30 步的内部优化(AdamW),然后把产生的「伪梯度」压缩后再上传给其他节点。压缩方式包括 Top-k 稀疏化(只保留最关键的梯度分量)、误差反馈(把被丢掉的部分存起来累积到下一轮)、以及 2 位量化。最终的压缩比超过 146 倍。
换句话说,原本需要传输 100MB 的东西,现在不到 1MB 就够了。
这让系统在普通互联网(上行 110Mbps,下行 500Mbps)的带宽限制下,把计算利用率维持在约 94.5%——20 个节点、每节点 8 块 B200、每轮通信耗时仅 70 秒。
Gauntlet 解决激励相容问题。 它运行在 Bittensor 区块链(Subnet 3)上,负责验证每个节点提交的伪梯度质量。具体方式是:用一小批数据测试「用上这个节点的梯度后,模型损失降低了多少」,结果称为 LossScore。同时,系统还检查节点是否在用自己分配到的数据训练——如果一个节点在随机数据上的损失改善比在自己分配数据上还好,会被打负分。
最终,每轮训练只选取评分最高的节点的梯度参与聚合,其余节点被淘汰出这一轮。超出的参与者会随时补位,使系统保持稳健。整个训练过程中,平均每轮有 16.9 个节点的梯度被纳入聚合,累计参与过的唯一节点 ID 超过 70 个。
去中心化 AI 的价值叙事,正在发生根本性转变
从技术和行业视角看这件事,Covenant-72B 代表的方向有几个真实的意义。
第一,打破了「分布式训练只适合小模型」的预设 。 尽管和前沿模型还差得远,但证明了这个方向的可扩展性。
第二,无许可参与是真实可行的 。 这一点被低估了。此前的分布式训练项目依赖白名单——只有经过审核的参与者才能贡献算力。SN3 这次训练中,任何拥有足够算力的人都可以接入,验证机制负责过滤恶意贡献。这是向「真正去中心化」迈出的具体一步。
第三,Bittensor 的 dTAO 机制让子网价值的市场发现成为可能 。 dTAO 允许每个子网发行自己的 Alpha 代币,通过 AMM 机制让市场来决定哪些子网获得更多的 TAO 排放。这为像 SN3 这样产出了具体成果的子网提供了一套粗糙但有效的价值捕获机制。当然,这套机制同样容易被叙事和情绪干扰,LLM 训练成果的质量很难被普通市场参与者独立评估。
第四,去中心化 AI 训练的政治经济含义 。 Jack Clark 在 Import AI 中把这个问题提升到「谁拥有 AI 的未来」这个层面。当前前沿模型训练被少数拥有大规模数据中心的机构垄断,这不只是商业问题,也是权力结构问题。分布式训练如果能持续取得技术进展,有可能在某些模型类型(如特定领域的小规模前沿模型)上形成真正去中心化的开发生态。当然,这个前景目前还远。
小结:一个真实的里程碑,以及一堆真实的问题
黄仁勋说,这像「现代版的 Folding@home」。Folding@home 在分子模拟领域做出了真实贡献,但它没有威胁到大型制药公司的核心研发地位。这个类比非常准确。
SN3 跑通了协议,验证了分布式训练的可行方向。但从技术和行业视角看,它交出的这份成绩单背后,还有一堆很少有人愿意认真讨论的问题:
MMLU 本身在学界也是一个充满争议的指标, 公开基准的题目与答案存在泄露进训练集的风险。更值得关注的是比较基线的选取:论文所对标的 LLaMA-2-70B 与 LLM360 K2 均为 2023 至 2024 年的老模型,而同一区间的 65 至 70 分,在问及 Grok、豆包时均被归为中下游与入门级水平,在 Claude 看来则属严重落后。若将其置于动态更新的榜单或具备抗污染设计的新一代基准之上,结论或许会更加诚实。
更关键的是, 决定模型能力上限的高质量数据 ——对话数据、代码、数学推导、科学文献,大概率在各大公司、出版机构和学术数据库手里。算力民主化了,数据端依然是寡头结构,这个矛盾没有被讨论过。
关于安全性 ,无许可参与意味着你不知道那 70 多个节点背后是谁,也不知道他们在用什么数据训练。Gauntlet 能过滤明显异常的梯度,但无法防范微妙的数据投毒——如果一个节点系统性地在某类有害内容方向多训练几轮,产生的梯度变化足够细微,能通过损失评分筛查,但对模型行为产生累积偏移。最终的问题是:在金融、医疗、法律这类高合规、安全要求的场景,使用一个由少数匿名节点参与训练、数据来源追溯不完整的模型,会带来怎样的隐患?
还有一个结构性问题值得直说:Covenant-72B 本身以 Apache 2.0 许可证开源,不使用 SN3 代币。 持有 SN3 代币,分享的是这个子网未来持续产出新模型所带来的排放收益,而不是模型被使用时的任何直接收益。 这个价值链条,依赖于持续的训练产出,以及 Bittensor 整体网络排放机制的健康运转。如果未来训练停滞,或者新的训练成果质量不达预期,代币的估值逻辑就会松动。
把这些问题列出来,不是为了否定 Covenant-72B 的意义。它证明了一件以前被认为不可能的事情可以做到,这个事实不会消失。但做到了,和它意味着什么,是两件不同的事情。
SN3 代币过去一个月上涨 440%。这中间的距离,可能并非单纯的炒作,而是叙事的速度总是快于现实的速度。至于这段距离最终会被现实填补,还是被市场修正消化,取决于 Covenant AI 团队接下来真正交出什么。
值得关注的是,Grayscale 已在 2026 年 1 月份提交 TAO ETF 申请,指向机构资本对这条赛道的进场信号。此外,2025 年 12 月 Bittensor 将每日 TAO 排放减半,供给端的结构性收紧还在发酵。
参考链接:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95