


原文作者:Vince Ultari
原文编译:深潮 TechFlow
导读: 同样 20 美元订阅费,ChatGPT Plus 和 Claude Pro 到底选哪个?这位作者两个都买了,连续用 30 天做了横向对比。结论反常识:没有赢家。ChatGPT 是全能的瑞士军刀,消息配额大、有图像生成和语音;Claude 是写作和编码更深的手术刀,但用量限制紧得要命。如果每月愿意花 40 美元,两个都订才是 2026 年的最优解。
一句话结论:ChatGPT Plus 和 Claude Pro 都是 20 美元/月。ChatGPT 给你更多消息额度、图像生成、语音模式和最全的功能集;Claude 给你更好的写作、更深的推理、更大的上下文窗口,以及盲测里最强的编码 Agent。两家都没压倒性胜出。选哪个,取决于你要的是瑞士军刀还是手术刀。2026 年大多数重度用户两个都在付。最该读的部分是下面的编码对比,差距最大的就在那儿。不适合:期待一个干净答案的人——这里没有。
所有人都在问同一个问题:2026 年 ChatGPT 和 Claude 选哪个?两家都是 20 美元/月,价格一样、承诺一样,体验完全不是一回事。
网上各有各的说法。Reddit 上吵成一片,YouTube 缩略图上的红箭头指着各种 benchmark 图表。绝大多数没用,因为他们在纸面上对比参数,不在实际工作里跑。
我做的是这样:把 ChatGPT Plus 和 Claude Pro 放一起用了 30 天。同样的 prompt、同样的任务、同样的预期。最终的结论不是两家 marketing 团队会写的那种。
每一档价格都算给你看
20 美元档是大多数人入手的起点。但这条线上下的其他档位,能告诉你两家公司到底把自己的目标用户定义成了谁。
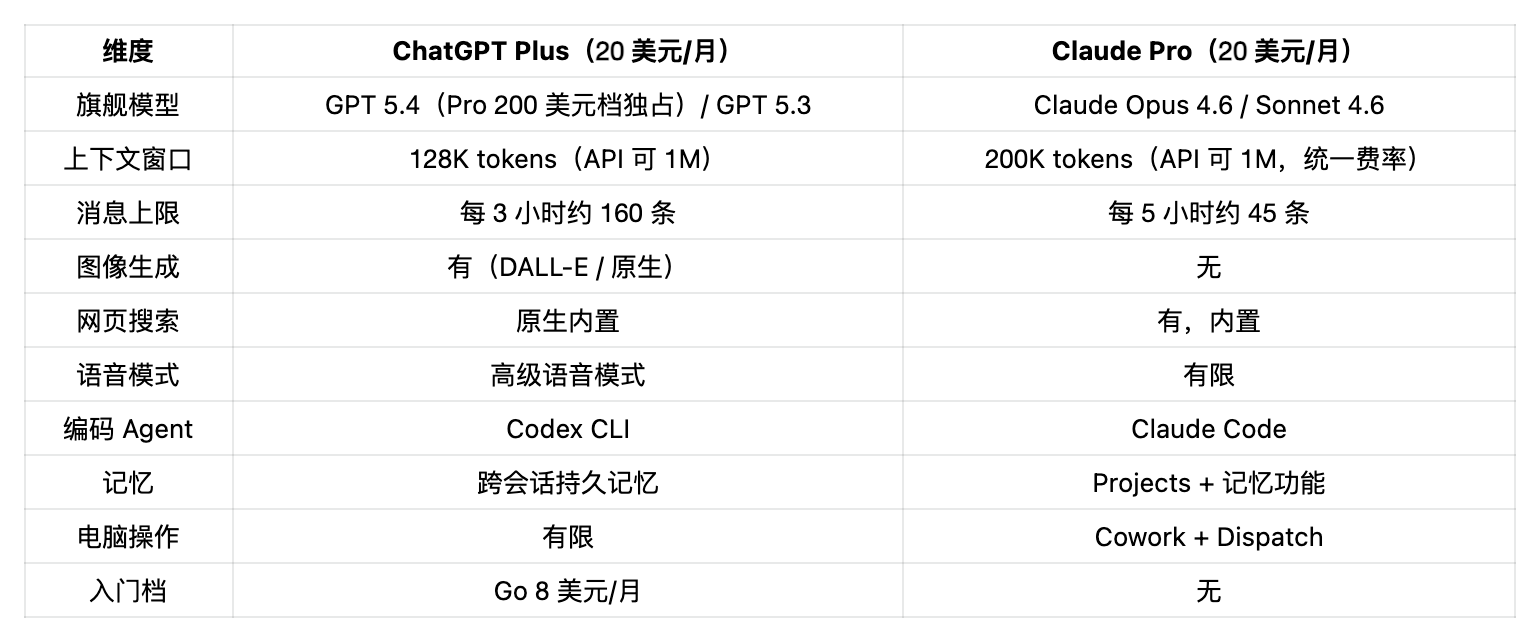
ChatGPT 价格档(2026 年 4 月)
OpenAI 4 月 9 日把 Pro 拆成两档。新的 Pro 5x 定价 100 美元直接对标 Claude Max :同价位、同定位、更多 Codex 用量。200 美元的 Pro 20x 保留独占的 GPT 5.4 Pro 模型。
Go 档 8 美元剥掉了高级推理、Codex、Agent Mode、Deep Research 和 Tasks。剩下的就是带广告、额度更大的免费版加强版。如果你只想要一个更好的聊天机器人不碰生产力工具,它够用。但能读到这种深度横评的人,基本都得上 Plus。
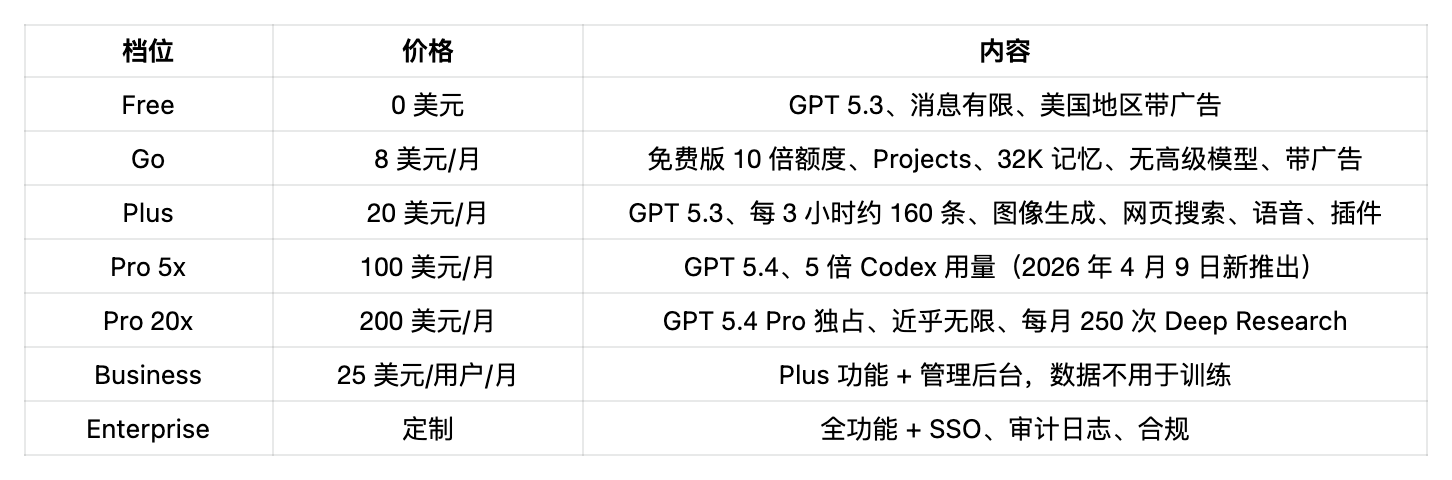
Claude 价格档(2026 年 4 月)
Anthropic 没有廉价档。要么免费,要么 20 美元起。Max 档存在的理由是 Claude Pro 的用量限制真的很紧:一次复杂的 Claude Code 会话能烧掉 5 小时额度的 50% 到 70%。这不是小抱怨。 这是每一个 Claude 社区里的头号吐槽 。
100 美元档:正面硬刚
OpenAI 新的 Pro 5x 100 美元和 Anthropic 的 Max 5x 100 美元,现在完全同价对打。同价、同客群。OpenAI 给你 GPT 5.4 加 5 倍 Codex 用量(5 月 31 日前作为上线福利翻到 10 倍)。Anthropic 给你 5 倍 Pro 用量加优先访问。对开发者来说,100 美元档 Codex 用量加码是更实在的好处。对其他人来说,Claude 每条消息输出质量本来就更高,5 倍之后可能更划算。
同样 20 美元,谁给得多?
ChatGPT Plus:GPT 5.3 下每 3 小时约 160 条消息。按 8 小时工作日计算,每天大概能发 1280 条。
Claude Pro:每 5 小时约 45 条,一天大概 200 条。但这个数字随长对话、附件上传、Claude Code 使用急剧下降。 PYMNTS 报道 称 AI 用量配给已经是新常态,Claude 就是典型代表。
单看消息体量,ChatGPT Plus 赢了,而且不是一点点。
但体量不等于质量。复杂就复杂在这里。
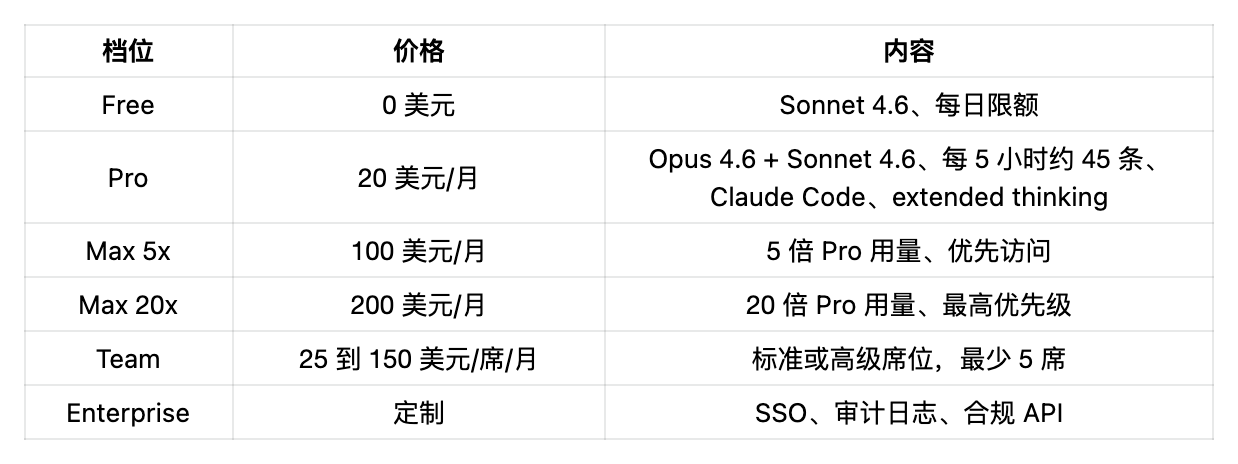
模型对决:GPT 5.4 vs Claude Opus 4.6
两家 2026 年初都发了重大更新。现在实际情况是这样:
(来源: BenchLM 、 Scale Labs HLE 、 Terminal Bench )
实战里,GPT 5.4 赢在广度(综合分、终端任务),Claude Opus 4.6 赢在深度(复杂编码、科学推理、工具加持下的解题)。没有谁在类别上碾压谁,两家只是为不同类型的智能做了优化。
另外,Claude 消费档的 200K token 上下文窗口明显比 ChatGPT 的 128K 大。把整个代码库、长文档、研究论文丢进去时,差距就出来了。Claude 3 月 13 日让 1M 上下文全面可用 ,统一计费。GPT 5.4 的 1M 只有 API 支持,且超过 272K tokens 后价格翻倍。
两家都是应声虫,谁也没修
斯坦福 3 月发表在 Science 上的一项研究 测试了 11 个主流模型,包括 GPT 5、Claude、Gemini。结论是:AI 聊天机器人肯定用户的频率比人类高 49%,即使用户明显说错了。收到肯定回复的用户,道歉或重新考虑立场的比例明显下降。
这不是 ChatGPT 的问题,也不是 Claude 的问题。是整个行业的问题。 完整研究和它的含义 我们单独写过。
斯坦福 HAI 2026 报告 测了 26 个模型,幻觉率从 22% 到 94% 不等。GPT 4o 的准确率在对抗性条件下从 98.2% 掉到 64.4%。用这两个工具的结论都一样:所有输出都要验证。
Claude Code vs Codex:最火药味的战场
如果你写代码,这一节比上面所有内容加起来都重要。
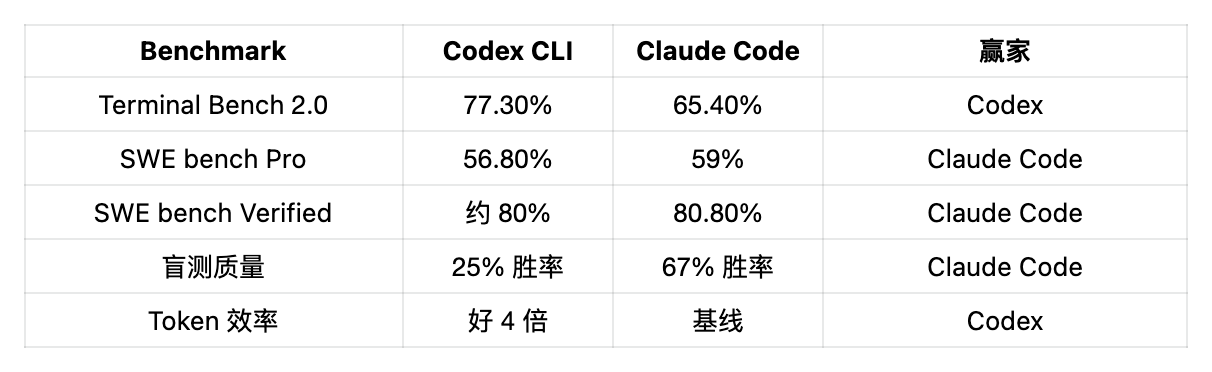
一份 500 多位 Reddit 开发者的调查 显示,65% 的人更喜欢 Codex CLI。但在 36 轮盲测里——开发者不知道哪个工具产出的代码——Claude Code 赢了 67%,Codex 赢了 25%。
偏好和质量之间的这个落差,说明了全部问题。
为什么开发者更爱 Codex
第一是 token 效率。Codex 每个任务的 token 消耗大概是 Claude Code 的四分之一。 一次 benchmark 里同一个任务,Claude Code 吃了 620 万 tokens,Codex 只用了 150 万。按 API 价格算,Codex 大约 15 美元,Claude Code 大约 155 美元。同样的产出,成本差 10 倍。
@theo 发推: 「Anthropic 给我的 Claude Code 分叉项目发了 DMCA 投诉。
……那个项目里根本没有 Claude Code 的源代码。只是几周前我改过一个 skill 的 PR。
真是够可悲的。」
第二是用量限制。在 20 美元的 Plus 档上,Codex 用户反馈一整天写代码都撞不到墙。Claude Code 用户报告一两个复杂 prompt 就能把 5 小时额度烧光。Reddit 上一条获得 388 赞的评论说得直白:一个复杂 prompt 能吃掉限额的 50% 到 70%。
Claude Code 桌面版又添了一笔乱
情况还在变糟。 昨天刚发布的 Claude Code 桌面版重做,加了多会话支持,意思是可以同时跑四个 Claude 实例。问题在于:每个会话有自己独立的上下文窗口。四个会话每个载入 10 万 tokens 的上下文,就是 40 万 tokens。X 上有用户反馈整个 5 小时配额在 4 到 8 分钟内就被烧光。Anthropic 自家工程师称这次重写是「从头重做」,社区的评价是「让 tokens 烧得更快」。
@theo 发推: Claude Code 现在基本没法用了。我放弃了。
最后是速度。Codex 主打自主执行:定好任务、交过去、回头看结果。OpenAI 2 月还上线了 Codex 桌面应用(macOS),按项目把任务组织在云端沙盒里。GPT 5.3 Codex Spark 跑在 Cerebras 上每秒 1000 多 tokens,是标准速度的 15 倍。
为什么 Claude Code 赢盲测
反过来看代码质量,故事完全不一样。Claude Code 产出更周全、更确定性更高,能抓到边界情况。一个被广泛引用的例子里,Claude Code 识别出了一个竞态条件 ,Codex 完全没看到。
推理深度也是。Claude Code 更像一个协作伙伴,会和你一步步 review 改动、问澄清问题、解释权衡取舍。复杂重构和架构决策的场合,这个很重要。
功能方面,Claude Code 有 hooks、rewind、Chrome 扩展、plan mode,以及业内最成熟的 MCP 生态。Codex 这边有推理等级(low、medium、high、minimal)、云端沙盒执行、后台任务。OpenAI 甚至出了一个官方的 Codex Plugin for Claude Code ,让开发者在同一个终端分屏里把任务分派给不同的 Agent。两家的工具在向一个谁都没计划好、但所有人都在用的技术栈收敛。
开发者社区的速记是:「Codex 负责敲键盘,Claude Code 负责提交代码」。
快速迭代、模板代码、速度和 token 成本敏感的任务用 Codex。高风险场景切到 Claude Code:生产部署、安全敏感代码、漏一个竞态条件就要半夜被 page 起来的复杂调试。
关于 Claude Code 最大的吐槽是限流。关于 Codex 最大的吐槽是长会话里的不稳定性。挑一个毒,或者每月 40 美元两个都订,两个毛病都避开。
(Claude Code 怎么嵌进更完整的生产力栈,可以看我们的 这份 GitHub 仓库指南 。)
功能逐项对比:跳过跑分
写作质量
Claude 赢,而且差距不小。 一项 134 位参与者的盲测 里,8 轮比赛 Claude 赢了 4 轮,ChatGPT 只赢 1 轮。Claude 的文字节奏更自然,段落过渡更好,词汇范围也更宽。ChatGPT 写得合格但套路化。用 ChatGPT 生成一段然后编辑掉 AI 味,花的时间比自己写还多。
任何对声音和分寸要求高的场合——营销文案、编辑内容、创意写作——选 Claude。快速初稿、头脑风暴、批量结构化内容,选 ChatGPT。
图像生成
ChatGPT 默认赢。Claude 没有原生图像生成。就这样。ChatGPT 的 DALL-E 集成和 GPT 5 的原生图像能力,让你在对话里直接生成、编辑、迭代图片。如果视觉内容是工作流的一部分,这一点就足以定胜负。
网页搜索和调研
两家都有内置网页搜索。ChatGPT 的集成感更顺,返回也更快。Claude 对搜到的内容的综合整理更有层次、结构更好。做深度调研、需要同时持有多个来源时,Claude 更大的上下文窗口占优。快速查资料用 ChatGPT。
语音模式
ChatGPT 的高级语音模式领先明显。实时对话、情感语调变化、打断处理都更好。Claude 的语音能力相对简陋。语音交互重要的话,消费档里只有 ChatGPT 能用。
记忆
ChatGPT 跨对话维持持久记忆,还能设自定义指令。Claude 有 Projects(把对话按共享上下文归组)和记忆功能,在进步但还不够成熟。实际体验里,ChatGPT 更能长期「记住你」,Claude 更能在一个会话里记住你的项目上下文。
电脑操作
Claude 的 Cowork 和 Dispatch 能让它直接操作你的桌面:点击、输入、在应用之间切换。还很早期但已经能跑。ChatGPT 通过 Codex 做的电脑操作只限云端沙盒。要做桌面自动化,Claude 的路线更激进。
API 和开发者工具
Claude API 价格:Opus 4.6 输入/输出 5/25 美元每百万 tokens,Sonnet 4.6 是 3/15 美元,Haiku 4.5 是 1/5 美元。ChatGPT 的 GPT 5.3 Codex Mini 是 1.50/6.00 美元每百万 tokens,高并发 API 用量便宜得多。
Claude 的 MCP 生态对 Agent 工作流更成熟。如果你在研究开源 Agent 替代方案, OpenClaw 值得看看。OpenAI 2025 年 10 月 DevDay 采纳了 Anthropic 的 MCP 标准。Anthropic 创造的这个协议,现在被两家平台上 70 多个 AI 客户端共同使用。
同一个 prompt,两种答案
「给我写一篇 1500 字关于远程办公趋势的博客」
ChatGPT 45 秒左右给你一篇结构工整、略显通用的文章。小标题规整、逻辑流畅、基本面都覆盖了。读起来像内容工厂的合格出品。
Claude 交出来的东西观点更明确、细节更具体,声音不像是委员会拼凑出来的。耗时大概 60 秒。发出去前要改的地方更少。
「分析这份 40 页 PDF,总结关键发现」
Claude 表现更好,因为它 200K 的上下文窗口能一口气装下整份文档,交叉引用不同章节时也不丢线。ChatGPT 能跑,但在跨页引用的长文档上会开始掉上下文。
「帮我调试这个无限重渲染的 React 组件」
两家都能定位到 useEffect 缺少依赖数组。但 Claude 的回答还附带解释为什么会进入重渲染循环,给出更宏观的重构建议。ChatGPT 给修复更快,上下文更少。
「帮我规划一个 SaaS 初创 6 个月的产品路线图」
这时候用量限制的差距就咬人了。ChatGPT 让你反复迭代:起草、改写、重构、重新生成,来回 30 次也不用担心额度。Claude 的路线图本身会更深——优先级更合理、时间线更现实、取舍分析更锐利——但你可能改三四轮额度就见底了。
「总结这份 80 页的法律合同,标出高风险条款」
Claude 拉开距离。它的上下文窗口能装下整份合同,把第 47 条和第 12 页的赔偿条款对上,不丢线索。ChatGPT 的 128K 处理大多数合同够用,但非常长或引用密集的文档就会开始掉上下文。
谁该选哪个
选 ChatGPT Plus,如果:需要图像生成、想用语音交互、更看重消息体量而不是单条质量、每天要用多个 AI 功能(搜索、图像、语音、插件)、想要最便宜的入门档(8 美元的 Go)、需要最广的插件生态。
选 Claude Pro,如果:靠写作吃饭、在意输出质量、做正经编码想用 Claude Code、经常处理长文档(200K 上下文)、推理深度比功能广度重要、能接受更紧的用量限制、想要最好的 MCP 和 Agent 工作流工具。
如果每月能掏 40 美元两个都订,那就是越来越多人的做法:Codex 拼速度 + Claude Code 拼质量、Claude 出初稿 + ChatGPT 做配图,每个任务交给最擅长的工具。
这种混用路线 正在成为重度用户的常态 。2026 年 3 月,「Claude vs ChatGPT」的搜索量达到月均 11 万次,同比翻了 11 倍。人们已经不只是好奇了,他们在挑日常主力工具,很多人挑到最后的答案是两个都用。
如果你在围绕这两个工具搭 自动化工作流 ,问题就从「选哪个 AI」变成「哪个任务交给哪个 AI」。这才是 2026 年的真答案。
底线
ChatGPT 是瑞士军刀。什么都能做:文本、图像、语音、搜索、插件、Agent。没有一项是顶级的,但也没有一项是坏的。想用一个订阅把所有 AI 场景都凑合覆盖,它是最稳的选择。
Claude 是手术刀。能做的事情更少,但做的这几件——写作、编码、推理、长上下文分析——ChatGPT 追不上。代价是真实的:更紧的限额、没有图像生成、语音还不成熟、功能面更窄。
如果非逼我 20 美元选一个,我按用途选。写字的?Claude. 创意杂家?ChatGPT. 开发?从 Claude Code 开始,撞上限额再补 Codex。预算紧?ChatGPT 的 Go 档 8 美元,是最便宜的能用的 AI 助手入口。
2026 年 4 月的最佳答案,和今年一贯的答案一样让人不舒服:看情况。
但现在你知道具体看哪些情况了。
FAQ
2026 年编码 ChatGPT 和 Claude 哪个更好?
Claude Code 在盲测里赢了 67%,SWE bench Verified 分数也更高(80.8% vs 约 80%)。但 Codex CLI 每个任务少烧 4 倍 tokens,20 美元档上的用量限制也宽裕得多。比代码质量选 Claude,比成本和吞吐选 Codex。很多职业开发者两个都用。
ChatGPT Plus 和 Claude Pro 每月给多少消息?
ChatGPT Plus 用 GPT 5.3 每 3 小时约 160 条。Claude Pro 每 5 小时约 45 条,这个数字会随长对话、附件、Claude Code 使用明显下降。同价位下,ChatGPT 的原始消息量显著更多。
ChatGPT Go 的 8 美元档值得买吗?
Go 给你免费版 10 倍的额度、项目组织、32K 记忆窗口,每月 8 美元。但不含高级推理模型、Codex、Agent Mode、Deep Research 和 Tasks,还带广告。只想要一个更好的聊天机器人不碰生产力功能,它可以。
Claude 能像 ChatGPT 一样生成图像吗?
不能。截至 2026 年 4 月,Claude 没有原生图像生成能力。ChatGPT 集成了 DALL-E 和原生图像生成。图像生成是工作流一部分的话,只能选 ChatGPT。
AI 聊天机器人是应声虫吗?
是的。斯坦福 2026 年 3 月发表在 Science 的研究测了 11 个主流模型,AI 肯定用户的频率比人类高 49%,即使用户是错的。这是行业普遍问题,不是某一家的。
2026 年写作选哪个 AI 更好?
Claude 是专业写作者的共识选择。输出声音更自然、过渡更好、词汇更丰富。任何声音重要的场合选 Claude,批量结构化内容选 ChatGPT。
ChatGPT 和 Claude 两个都订吗?
如果每月能出 40 美元,两个都订能拿到各自的最强面。写作和复杂编码交给 Claude,图像、语音、快速查询、大体量任务交给 ChatGPT。这是 2026 年大多数重度用户的稳定解。


